
Von Stefan Habermacher
28 Dezember 2021This article shows how to efficiently feed data flows into a relational database system in near real time. This means that the data is loaded and processed when it occurs and is quickly available to the company for analytical purposes. This approach is referred to as real-time / near real-time processing. In contrast to (near) real-time loads are batch loads, in which data is loaded and processed at time X (for example, daily or weekly) in correspondingly large quantities. So instead of working with data that can be over 24 hours old, (near) real-time processing allows you to use very recent data. This enables companies to react faster and significantly increases the timeliness of the information content. Data from different source systems can be loaded and processed via the same stream.
Specifically, we will show how Exasol can work together with the streaming platform Kafka. In the following use case, the integration of Exasol as a sink and source system, i.e. as a target or source system, for Kafka is presented and implemented in a test example.
Exasol is a database (RDBMS) developed and optimized for analytical purposes. Exasol uses column-oriented storage and in-memory technology. This allows data compression and offers performance advantages over other storage media such as hard disk drives (HDDs) or solid state disks (SSDs). Furthermore, Exasol offers parallelization and appropriate load balancing to further optimize performance. This makes Exasol an ideal sink or source system for streaming platforms like Kafka.
Objective
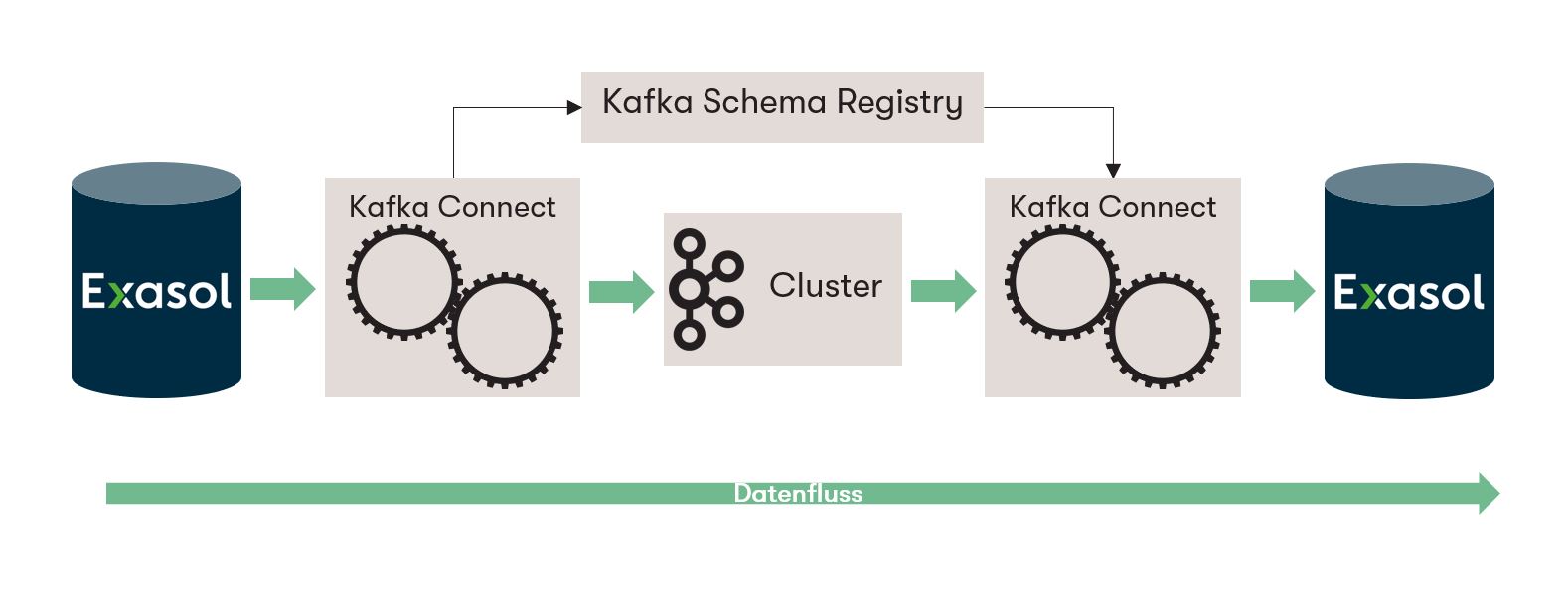
In order to use Exasol as a sink as well as source system and to simulate this in a runnable environment, the following components are important:
- Exasol DB Instance
- Kafka Manager
- Kafka Zookeeper
- Kafka Connect and Kafka Connect UI
- Kafka Schema Registry
- Kafka Broker
The Schema Registry and Kafka Connect play a central role here:
Among other things, the Schema Registry [1][2] manages the data structures and forwards them to the Sink Connectors. In addition, it enables schema evolution under certain conditions [3]. This means that changed data structures (e.g. a column is added or deleted in the source) are automatically recognized and a new version of the schema is created. Thus errors can be prevented and the stream continues to run.
Kafka Connect is responsible for reading, writing, serializing, deserializing the data. During serialization structured data is converted into a byte stream, during deserialization exactly the opposite happens. In addition, it is possible to perform certain transformations. The key components can be summarized as follows [4]:
- Connectors - the JAR files that specify how to integrate with the datastore itself
- Converters - handling serialization and deserialization of
- Data Transforms - optional manipulation of messages
In simpler terms, the connector speaks the language of the sink or source system (e.g. Exasol) and can read or write to it. But Kafka can't do anything with that, because Kafka only stores Key Value Pairs in form of bytes. Key Value Pairs are so-called key-value pairs. This corresponds to two linked data elements. The key is used for identification and the value represents the information. This process, the serialization and deserialization, is taken over by the converters. There are different serialization formats which are supported by Kafka Connect such as Avro, JSON or Protobuf.
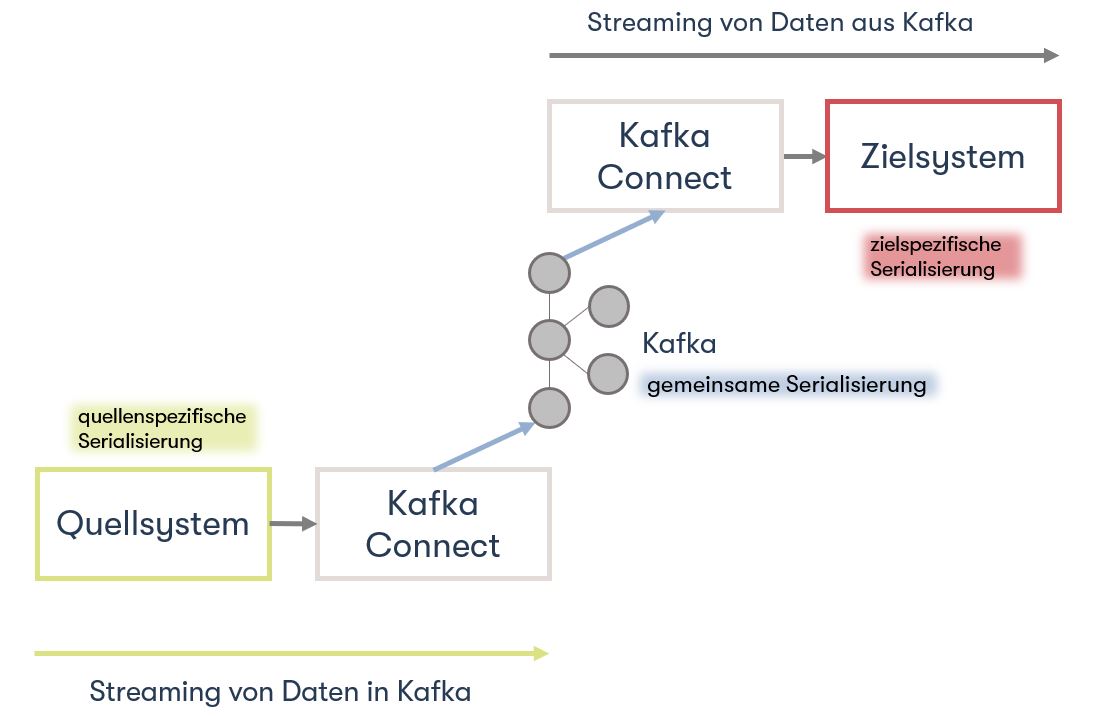
PoC Implementation
With the standard JDBC driver, which must be installed on Kafka Connect, Exasol can already be implemented as a source system. However, an extension of the standard driver is necessary so that Exasol can also be used as a sink system. For this purpose there is an open source project, a software with publicly available source code. All necessary information can be found here: Apache Kafka Integration | Exasol Documentation
A detailed guide to implement the integration: GitHub - exasol/kafka-connect-jdbc-exasol: Exasol dialect for the Kafka Connect JDBC Connector. There you can also find a YAML file. To easily and quickly start all necessary Docker containerts.
In order to be able to use Exasol as a sink or source system, the corresponding connectors must of course be created:
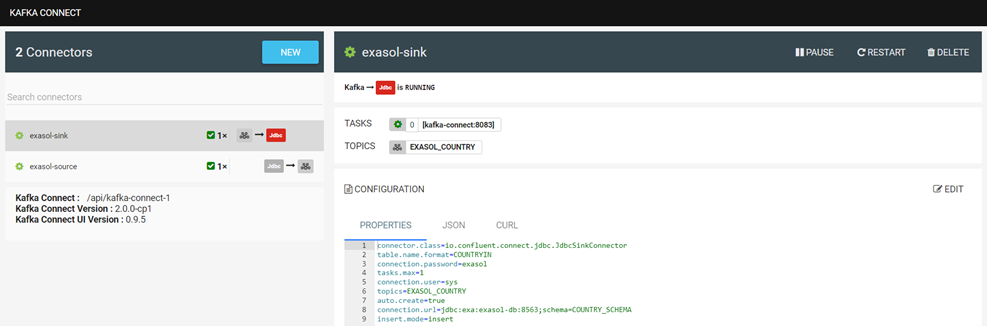
There are different configuration options for the properties. More details about this: JDBC Sink Connector Configuration Properties | Confluent Documentation
Once everything has been deployed and the connectors are running, it is relatively easy to test the setup. In the following graphic, different values are inserted into the table COUTRY in the left half using Python and pyexasol. In the right half an Avro deserializer is running, which deserializes and outputs the values according to the scheme:
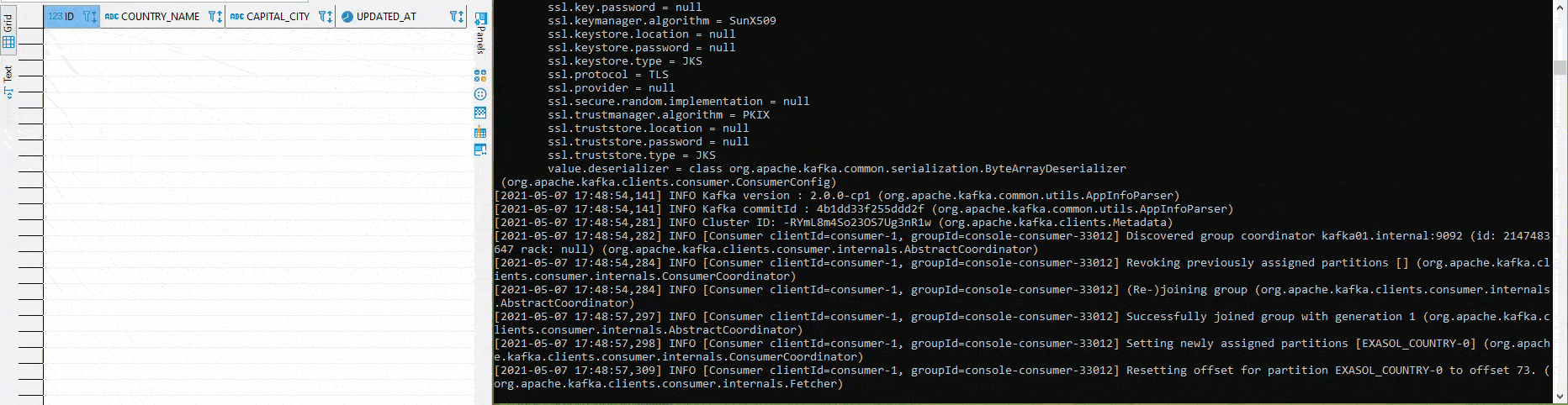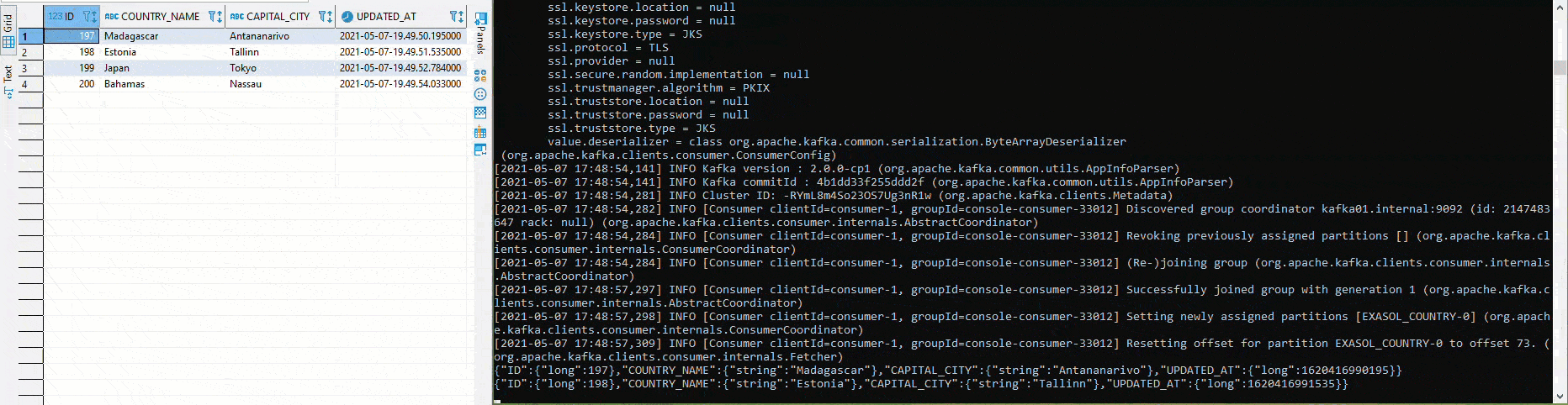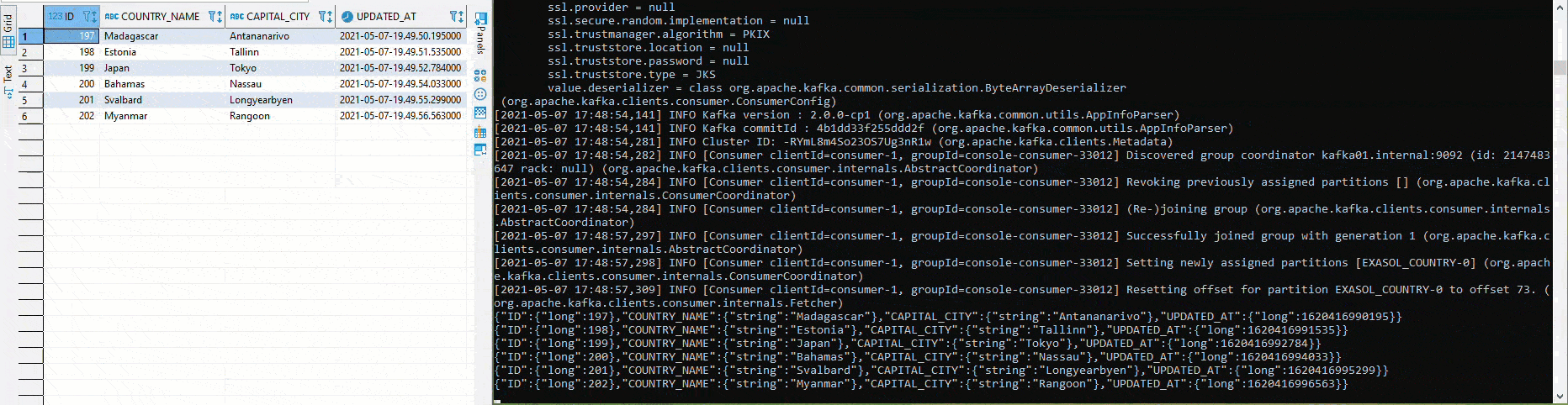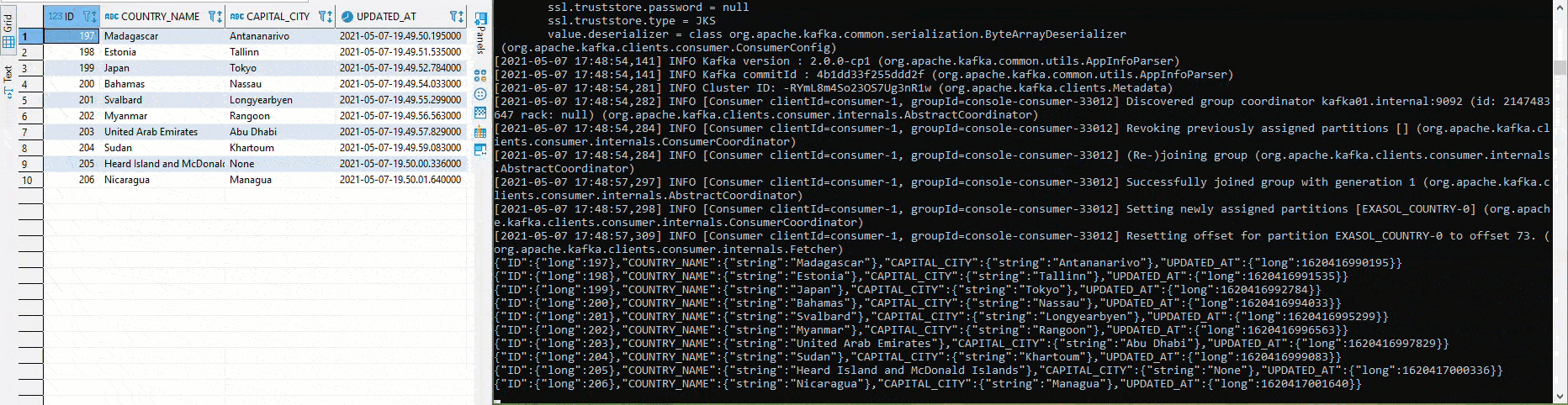
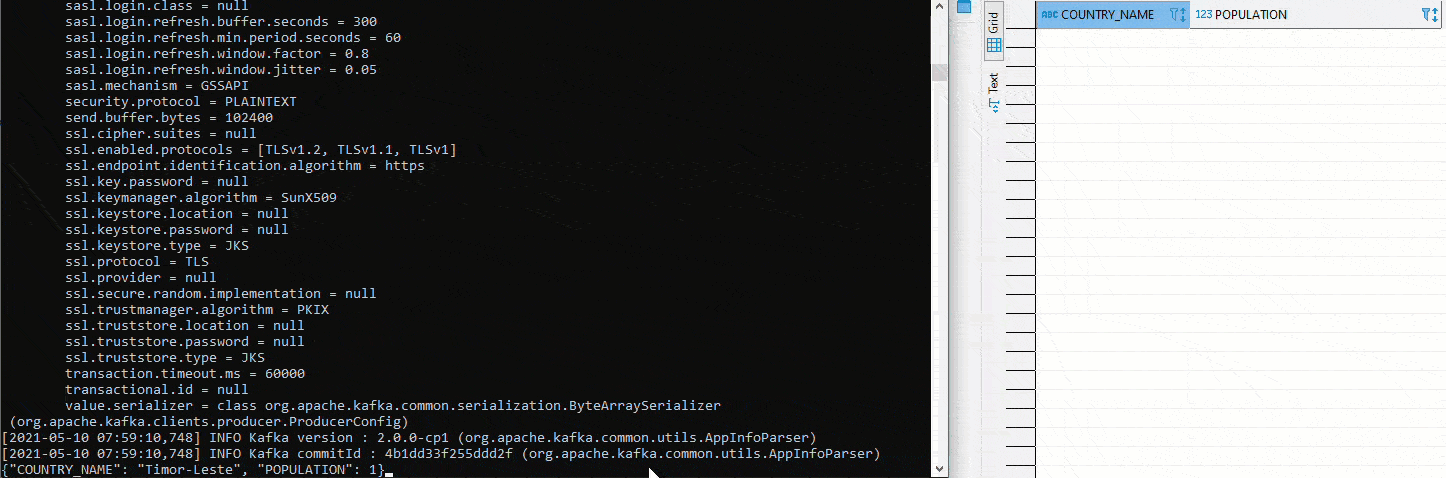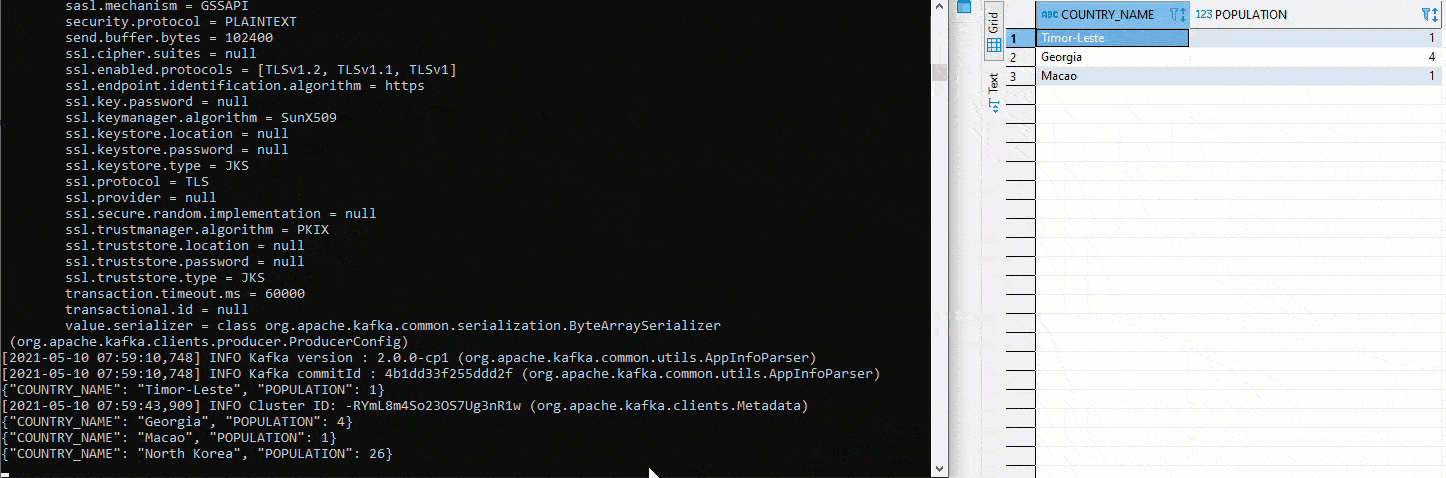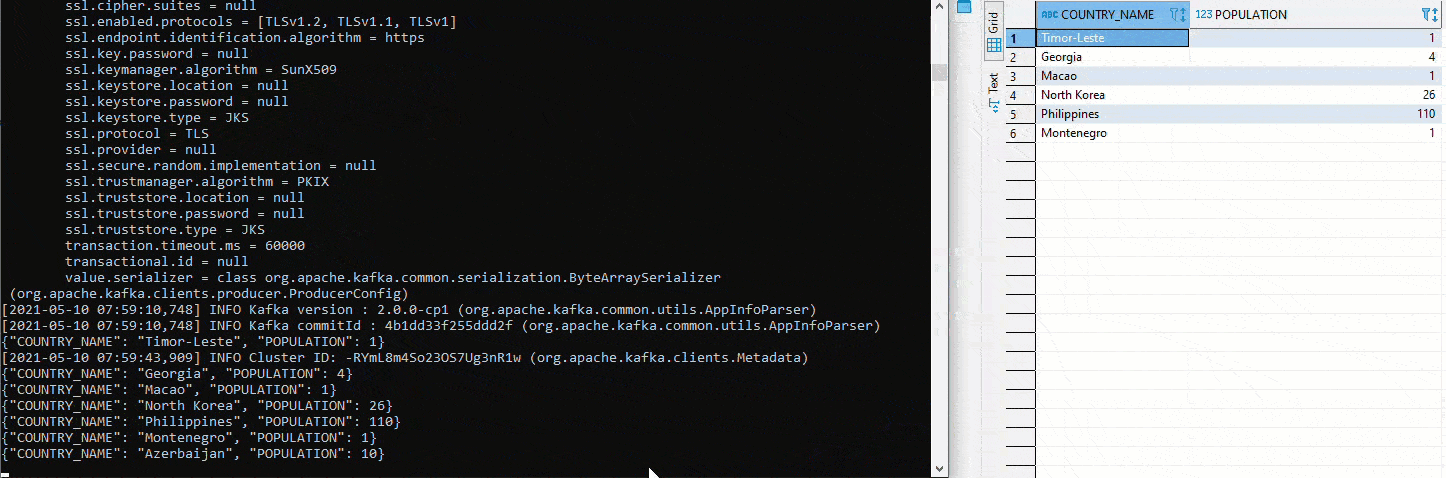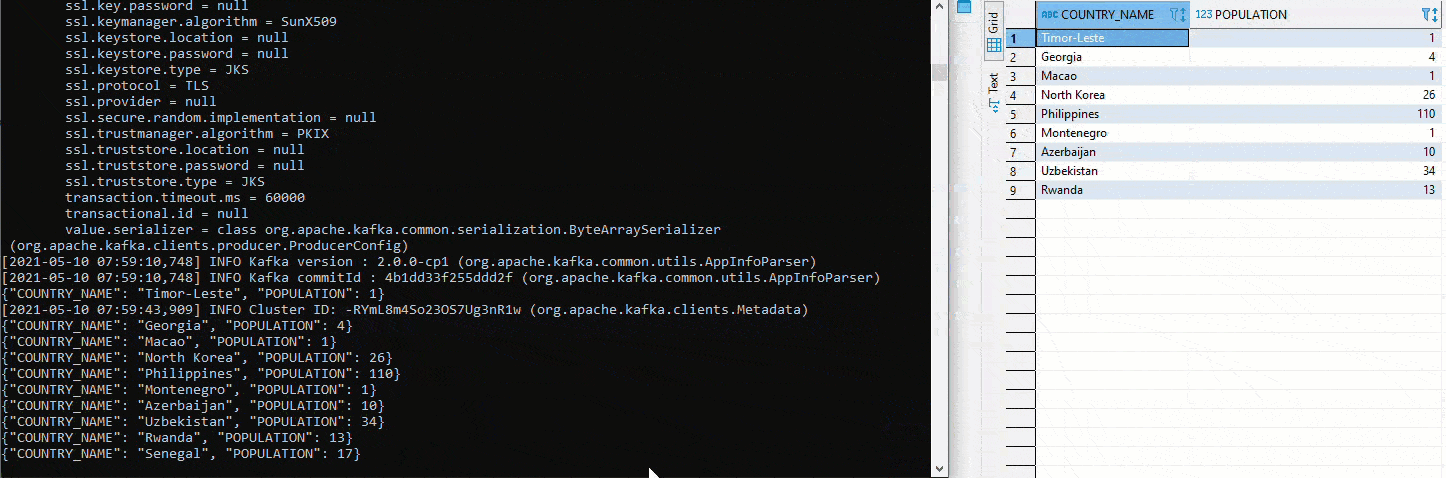
For example, a new column "POPULATION" can be added to the table "COUNTRY" without the need for manual adjustments to the source connector. The schema is automatically adapted, if compatible according to the settings, and a new version is created:

To test the setup for Exasol as a sink, you can start a Kafka Avro Console Producer on the schema registry and insert values in the appropriate format. In the following graphic this is also illustrated using Python. On the left side you can see the Avro Producer. There values are inserted via copy paste. On the right side the defined table in the connector:
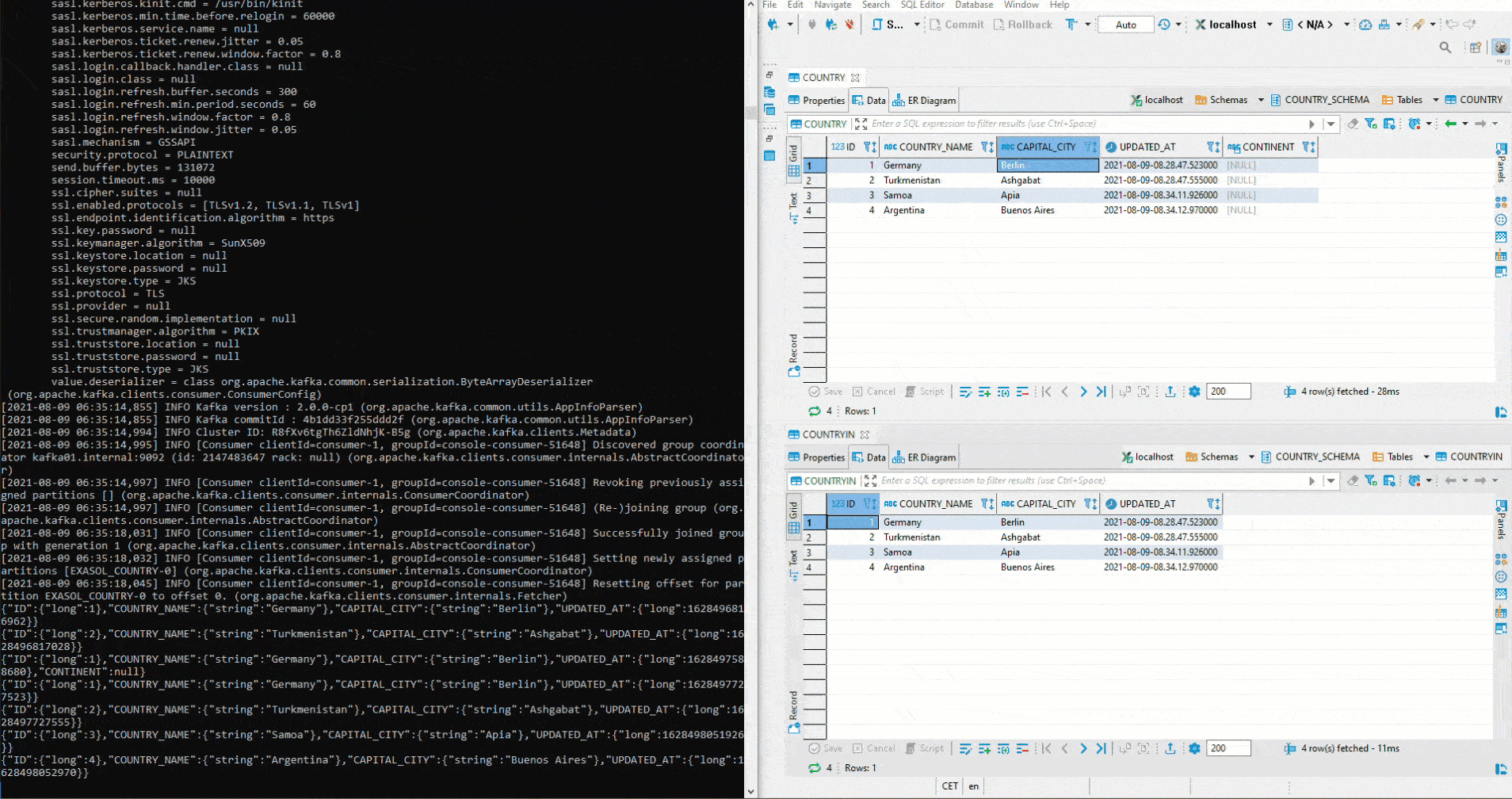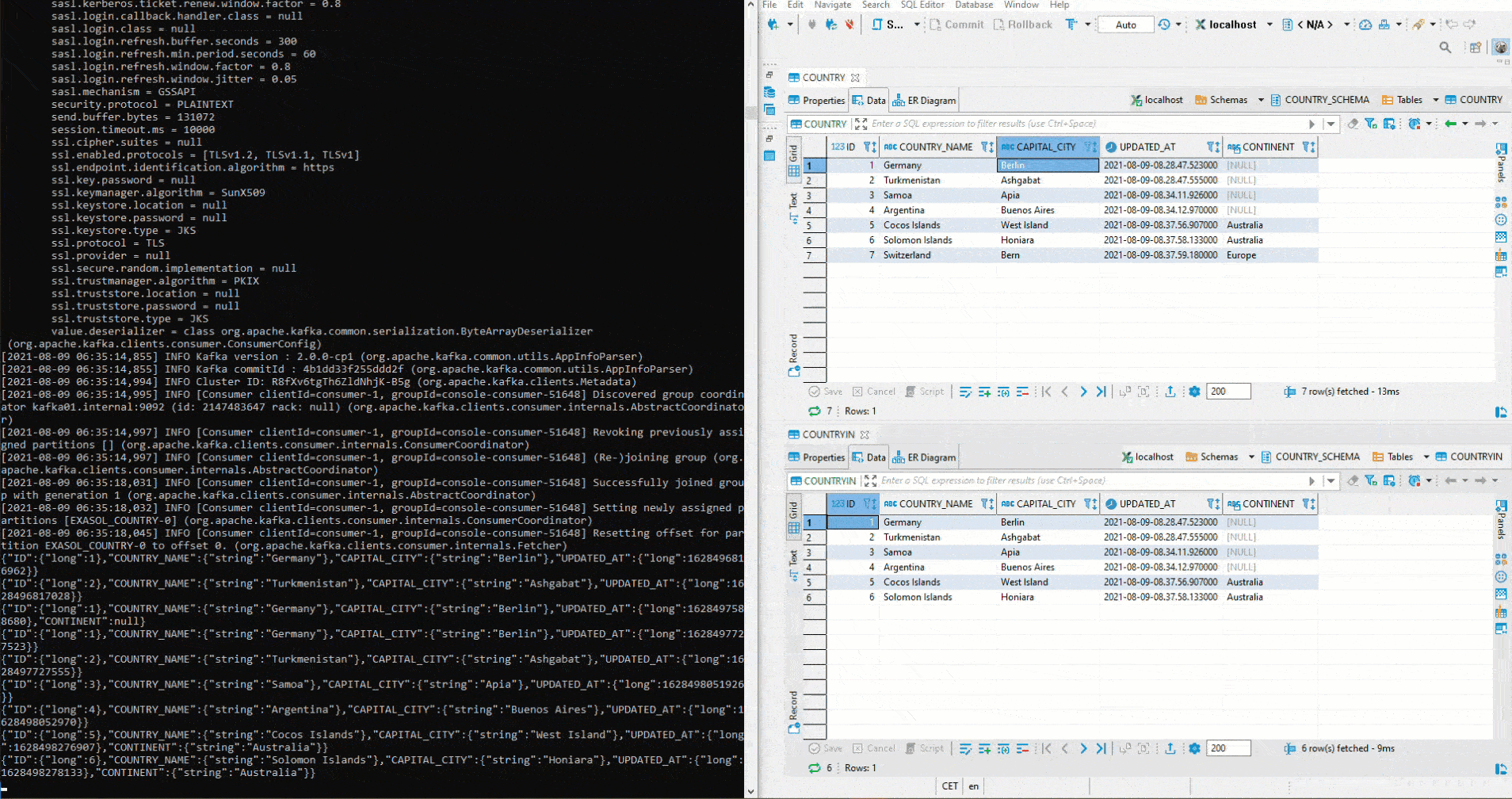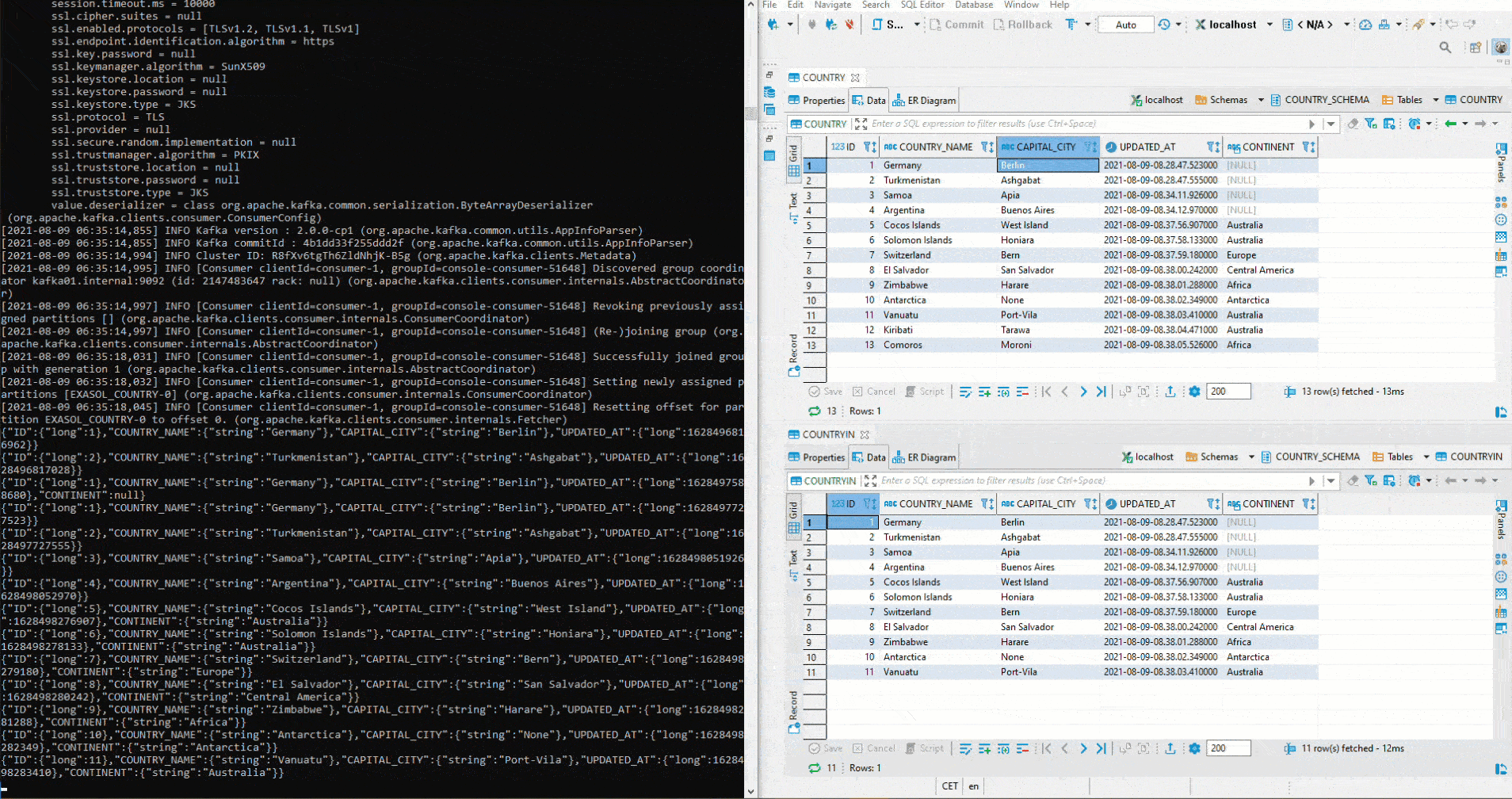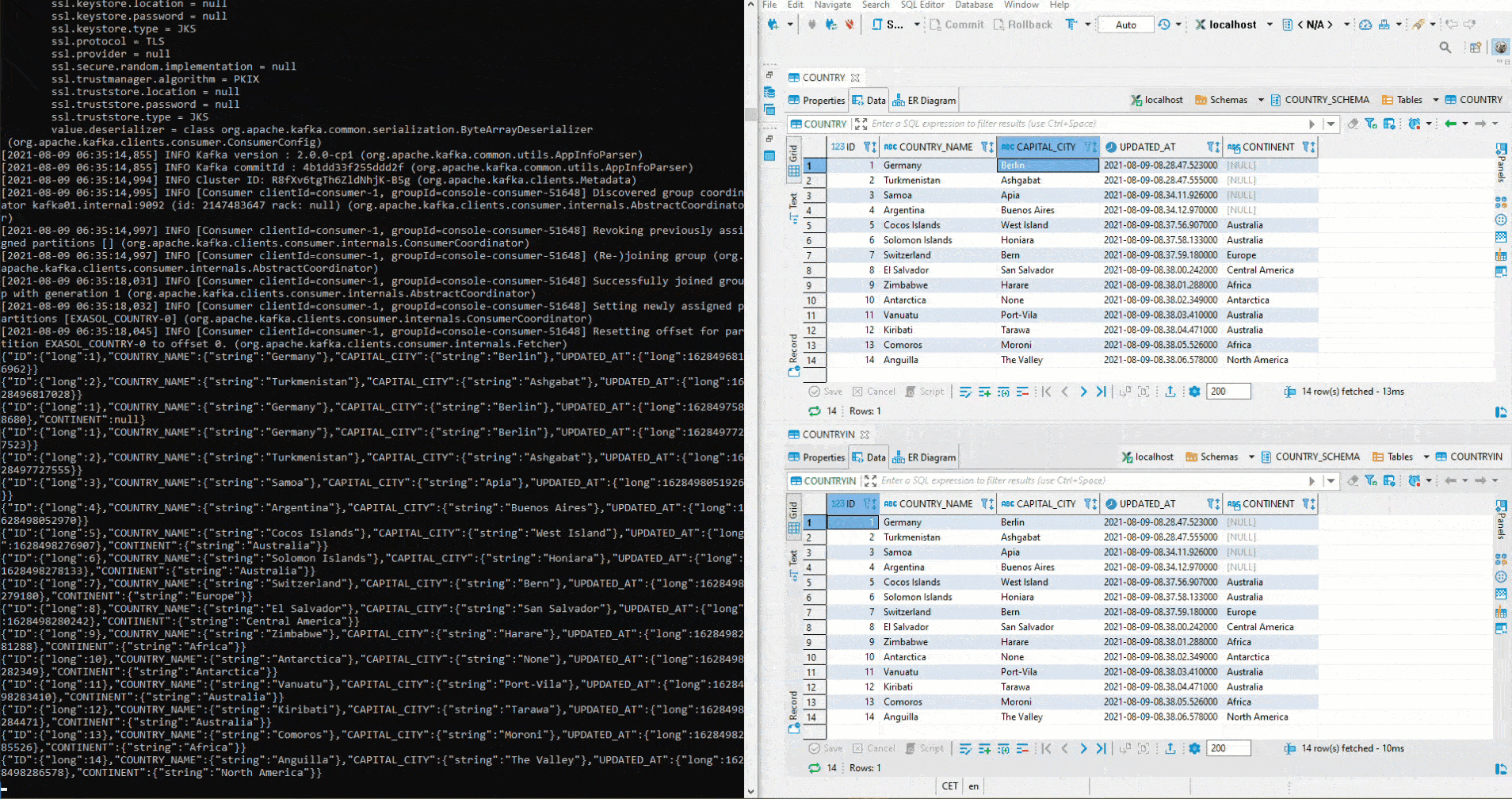
Here we tested with two different topics. To implement the initial defined setup, a cluster must first be created in Kafka Manager. Then both connectors are set to the same topic. Since auto.create was set to true on the sink connector, the sink table is created automatically. Now we start again an Avro Deserializer on the Schema Registry. On the right side we see the table COUNTRY. There again values are inserted by Python. Below is the table COUNTRIN which has been defined as the target table for the sink conncetor. Thus the data from COUNTRY flows into the Kafka Cluster and from there further into the COUNTRIN Table.
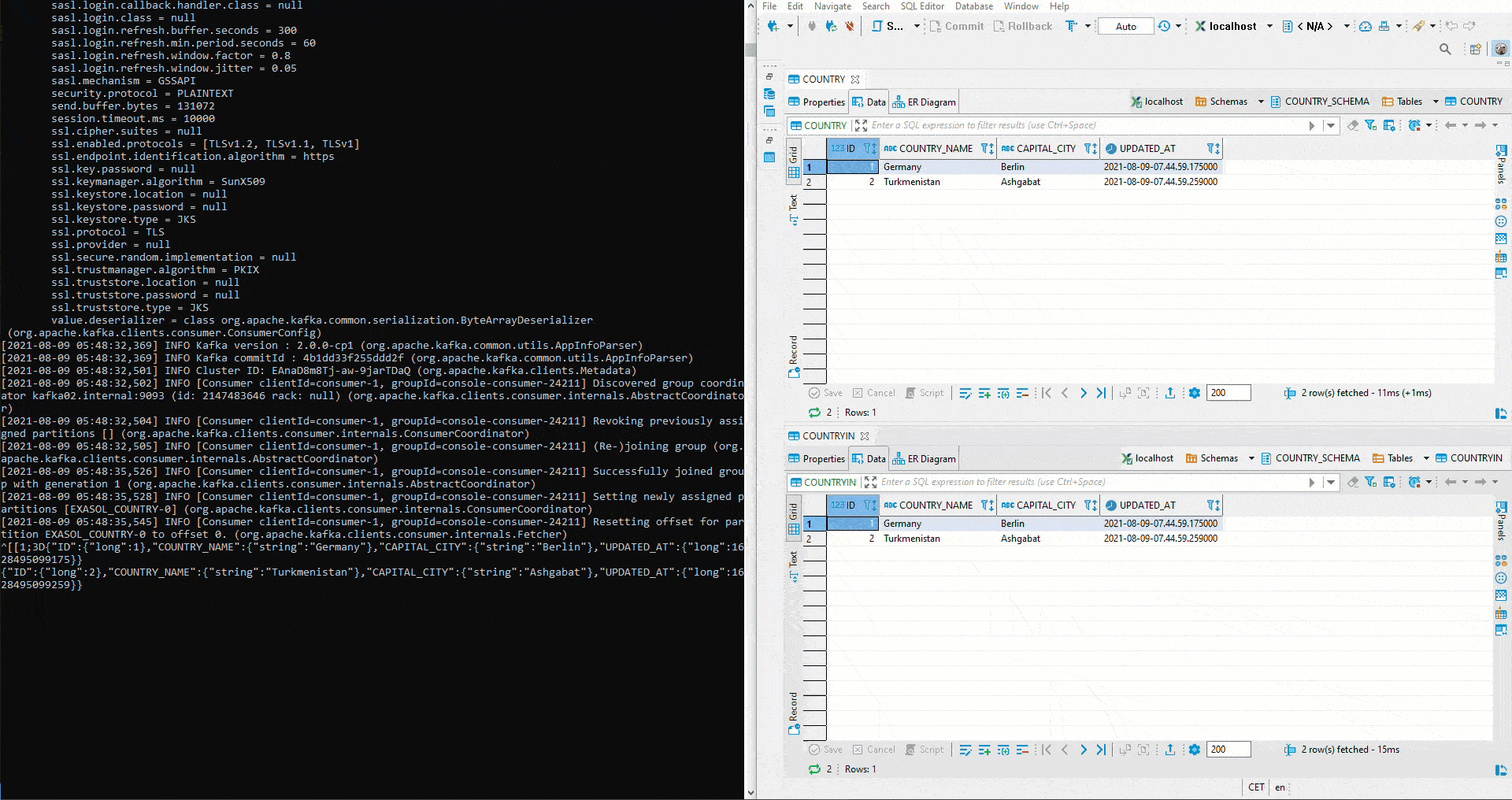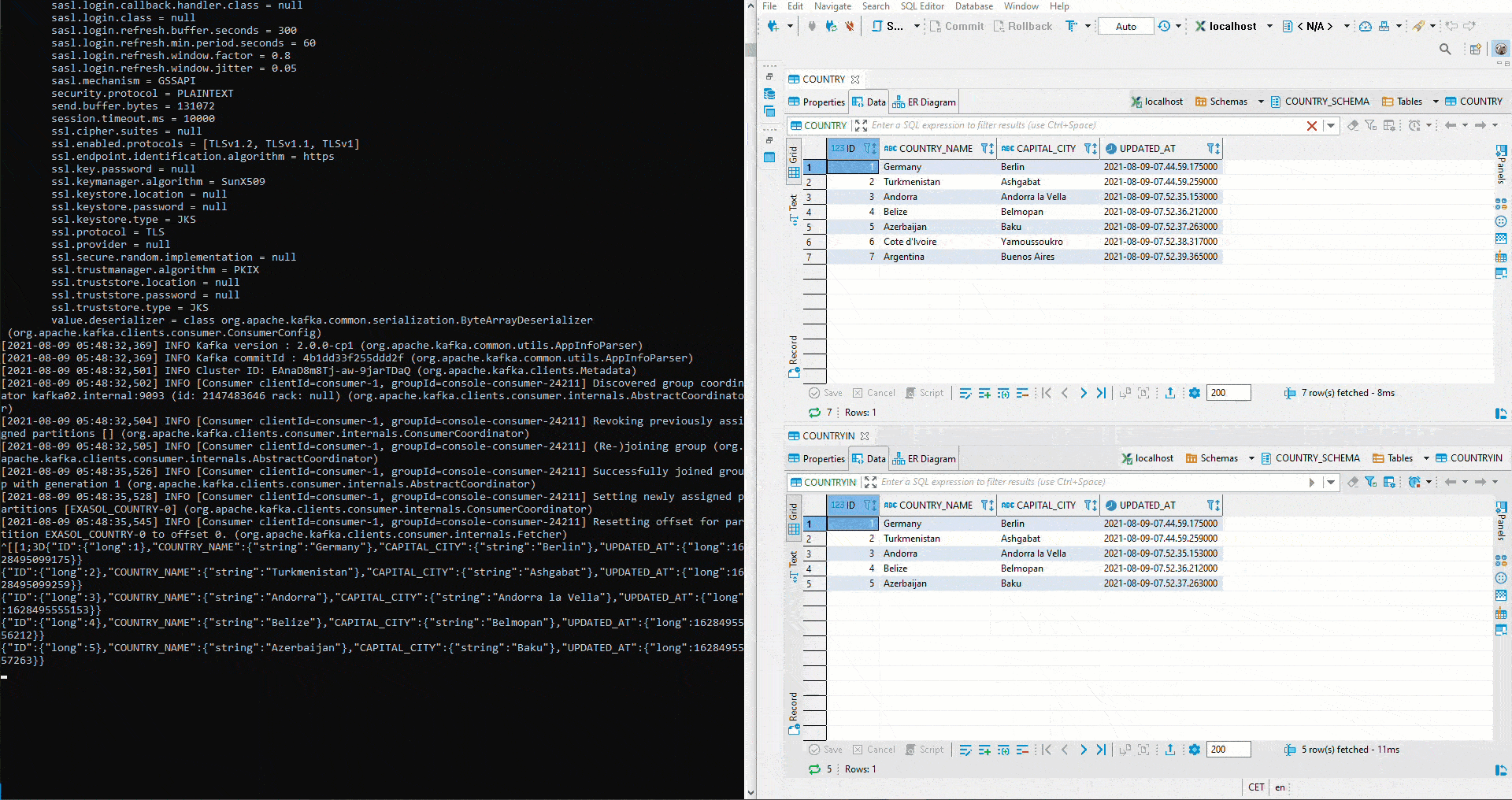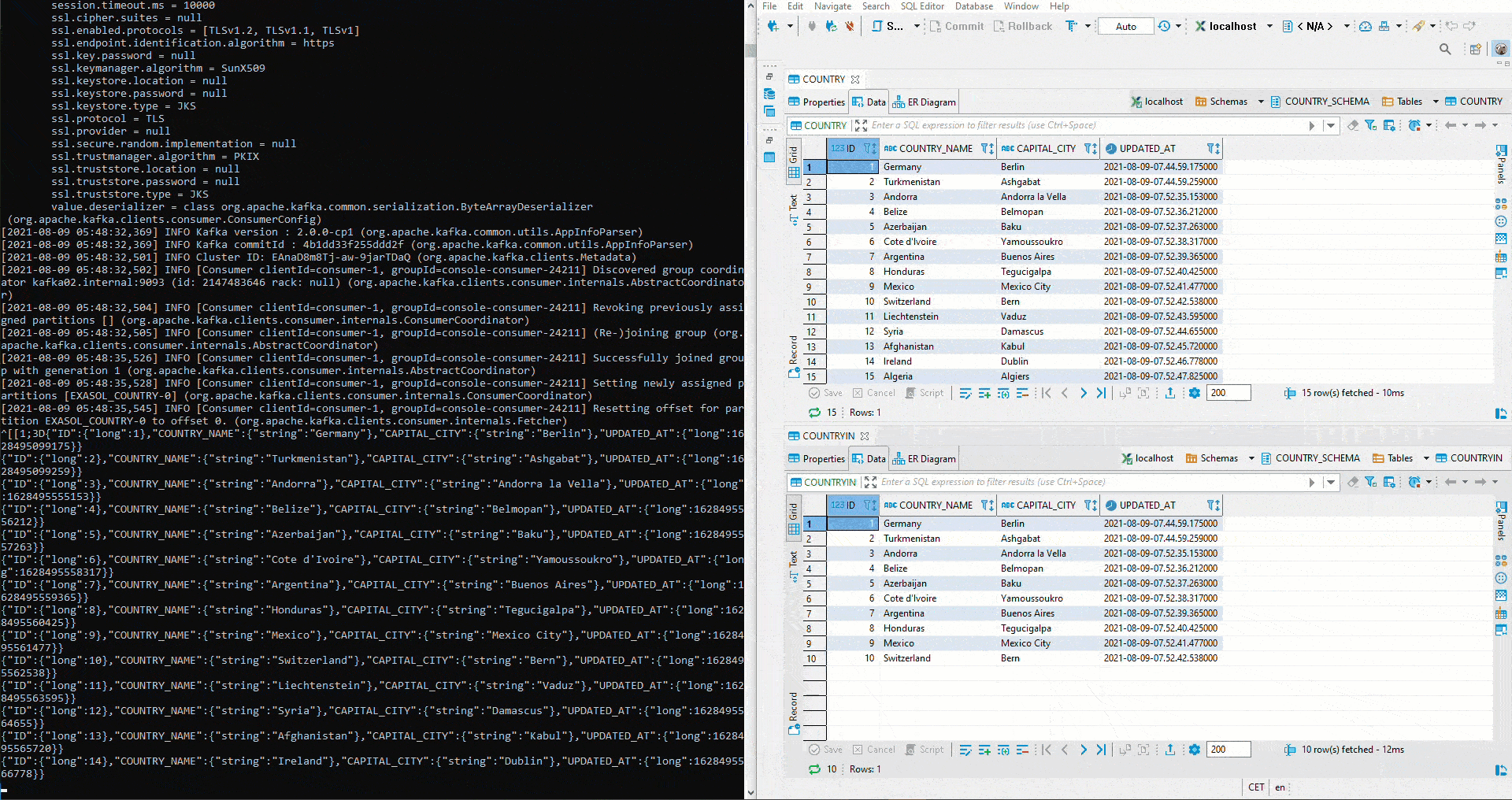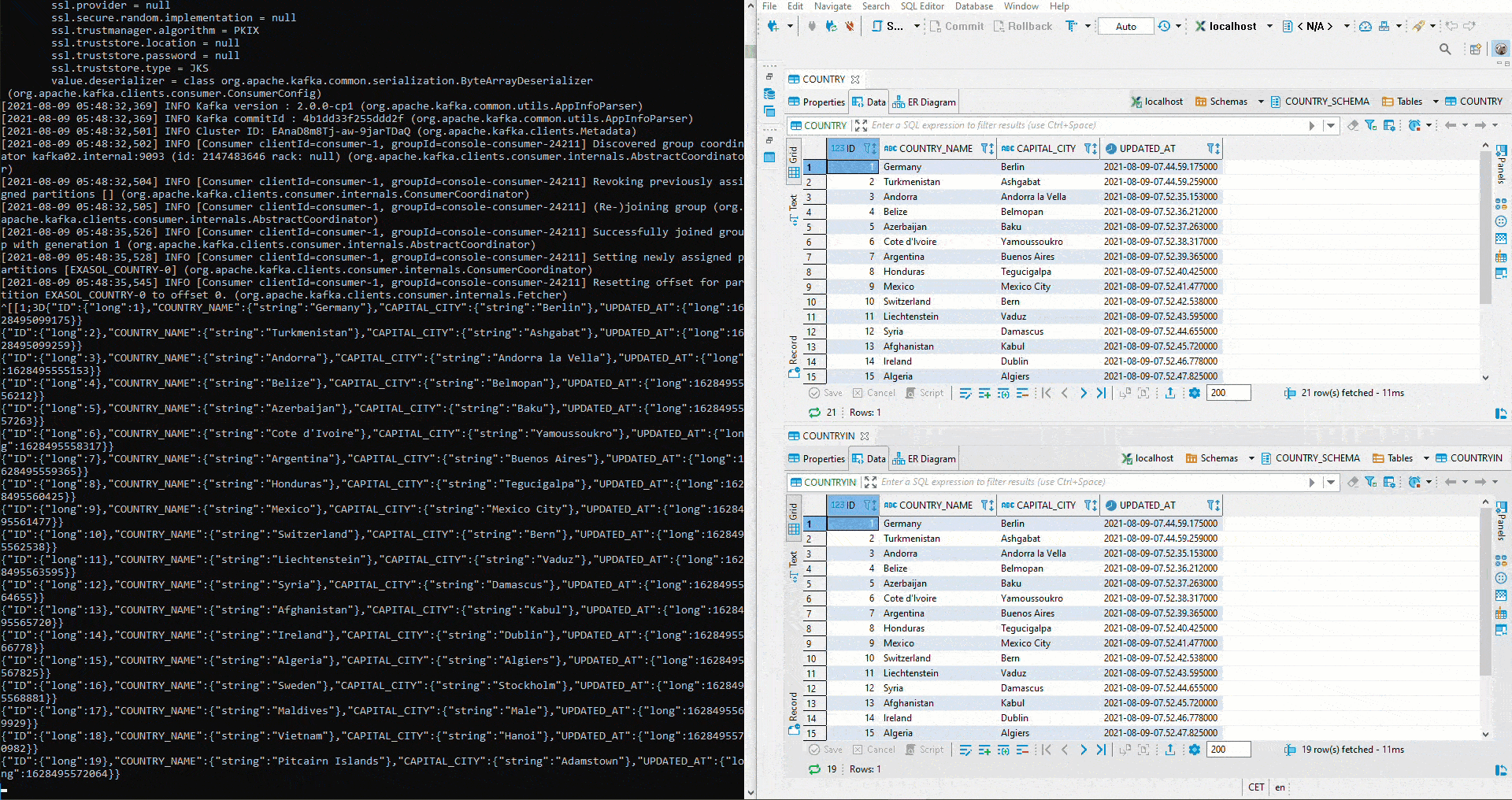
But how does the Sink System behave with respect to modified schemas? First, the parameter of auto.evolve in the Sink Connector is set to true:
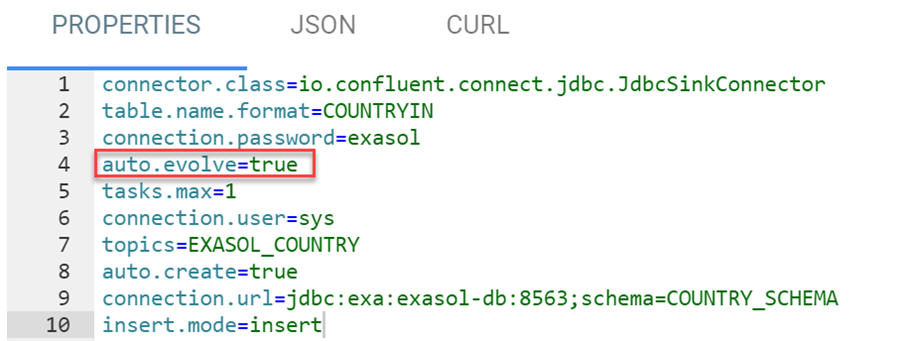
Afterwards a column CONTINENT is added to the source table COUNTRY. After that we start the Python script for the inserts again - including the continent. As you can see, the column is automatically created in the sink table COUNTRYIN and the data is inserted:
On the Schema Registry, version 1 as well as latest can be displayed via API (Application Programming Interface):
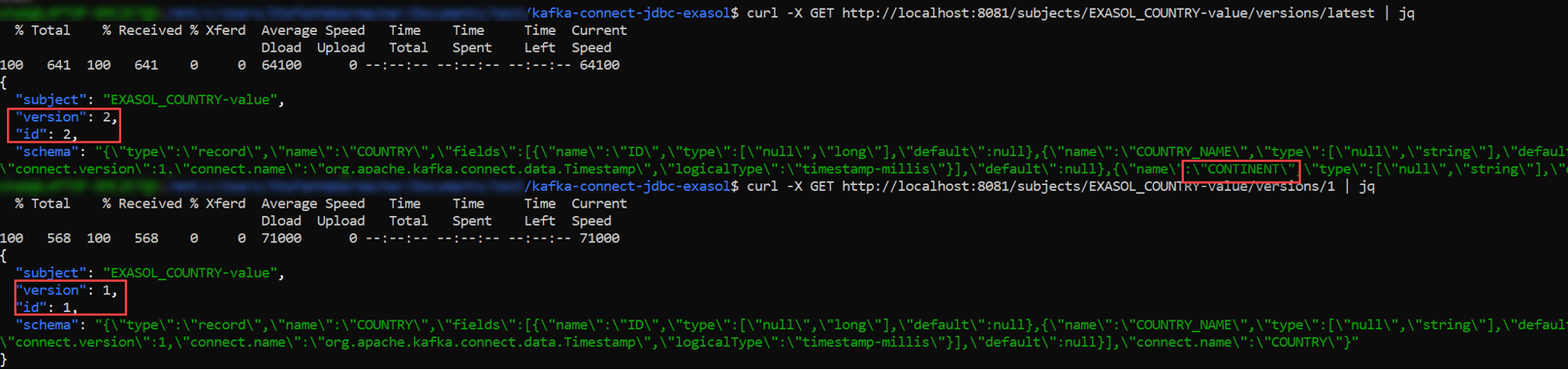
As you can see, in version latest (2) the CONTINENT column is visible - this is not the case in version 1.
Conclusion
Basically, it can be said that an executable implementation can be provided quickly and easily - thanks to the open source connector of the Exasol community. At the same time you have to keep in mind that this is version 1 and there are certain limitations. For example, no batch.size > 1 is supported in upsert mode. This means that it has to be checked and written row by row. This can lead to performance problems when dealing with larger amounts of data.
Do you find it exciting to always have up-to-date data sets available and would like to find out how this is possible with your company's systems?
We at Banian AG will be happy to help you with an initial consultation. Contact us by phone +41 (0)61 551 00 12, per Mail , or simply send us a message here on LinkedIn.
And if your interest goes beyond (near) real-time processing with Kafka, we are happy to help as a Digitalisierungspartner from the Strategy about the Information Management up to Data & Analytics.
For those interested to review and read more
Links:
GitHub - exasol/kafka-connect-jdbc-exasol: Exasol dialect for the Kafka Connect JDBC Connector
How to integrate Apache Kafka and Exasol
Literatur:
Schema Registry Overview | Confluent Documentation
Using Kafka Connect with Schema Registry | Confluent Documentation
Schema Evolution and Compatibility | Confluent Documentation
Begriffserklärungen:
|
Sink |
Target system for the data flow from Kafka |
|
Source |
Source system for the data flow in Kafka |
|
Parallelization |
Simultaneously improve ongoing processes or processing steps and performance |
|
Load distribution |
Processes are distributed across multiple instances of a system |
|
Serialize |
Conversion of structured objects into a byte stream |
|
Deserialize |
Conversion of a byte stream into a structured object |
|
Key Value Pairs |
Key-value pair, corresponds to two linked data elements. Here key serves for identification and the value represents the information |
|
JDBC-driver |
Java Database Connectivity Driver, serves as a basic interface between Java-based applications and databases. |
|
Open source project |
Software with publicly available source code |
|
Kafka Avro Console Producer |
Command line based Kafka application to read data into a Topic and convert it to Avro |
Bilder-Gallery