Von Roman Stalder
29 Juli 2020Willst Du wissen, wie Process Minning konkret funktioniert, wo es eingesetzt wird, was der Nutzen davon ist und welche Voraussetzungen dafür erfüllt sein müssen? Dann bist Du hier genau richtig.
Im Folgenden werden diese Fragestellungen anhand eines echten Use Case «Order2Invoice» mit anonymisierten Daten eines Handelsunternehmens step-by-step erklärt. Damit Du danach Deine ersten Erfahrungen selbst sammeln kannst, nutzen wir Celonis Snap, das kostenlose Process-Mining-Tool von Celonis.
Da Process Mining keine Plug-and-Play Technologie ist und die Daten meist nicht in passender Form vorliegen, setzen wir den Alteryx Designer für die Datenaufbereitung ein.
Egal, ob Du durch Process Mining neue Prozesse entdecken, die Konformität prüfen, oder Dein Prozesswissen erweitern willst, bedarf es zumindest einer groben Definition, welche Prozesse man analysieren möchte und welche IT-Systeme diese unterstützen. Die Ereignisdaten aus den relevanten IT-Systemen müssen drei Anforderungen erfüllen. Benötigt werden im Minimum eine Case-ID, ein Zeitstempel sowie eine Aktivitätsbezeichnung. Wenn die Datenqualität, -integrität sowie -schutz erfüllt sind, steht dem Einsatz von Celonis Snap nichts mehr im Wege und es können erste Analysen durchgeführt werden.
Schritt 1: Ist-Prozesse dokumentieren
a.) Zu analysierende Prozesse bestimmen
b.) Aktivitäten definieren
c.) Systeme definieren
Schritt 2: Log-Files bzw. Ereignisdaten aus den relevanten IT-Systeme organisieren und aufbereiten
a.) Daten bzw. Input-Files organisieren (.xlsx oder .csv)
b.) Case-ID definieren
c.) Zeitstempel definieren
d.) Daten aufbereiten
e.) In Schritt 1 definierte Aktivitäten hinzufügen
f.) Daten zusammenführen, anonymisieren und prüfen
g.) Output-Files generieren (.csv)
Schritt 3: Prozessanalyse mit Celonis Snap durchführen
a.) CSV-Files hochladen
b.) «Case ID», «Activity» und «Timestamp» manuell zuweisen
c.) Prozesse analysieren
Use Case «Order2Invoice»
Schritt 1: Ist-Prozesse dokumentieren
a.) Zu analysierende Prozesse bestimmen
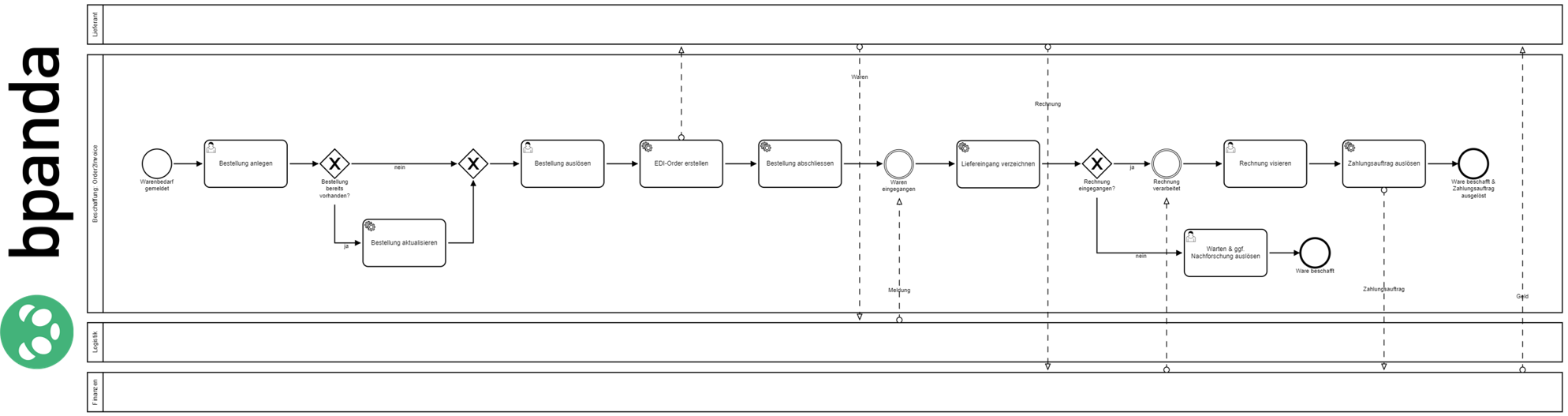
Beschaffung: Order2Invoice
Beschreibung: Durch eine Meldung eines Warenbedarfs beschafft der zentrale Einkauf die entsprechenden Waren bei den jeweiligen Lieferanten in Abstimmung mit den Finanzen und der Logistik.

Um die Aktivitäten zu definieren, haben wir den Prozess «Beschaffung: Order2Invoice» nach BPMN 2.0 modelliert. Diese visuelle Darstellung wird uns bei der folgenden Definition der Zeitstempel sehr hilfreich sein.
- ERP
- EDI-System
Schritt 2: Log-Files bzw. Ereignisdaten aus den relevanten IT-Systeme organisieren und aufbereiten
a.) Daten bzw. Input-Files organisieren (.xlsx oder .csv)

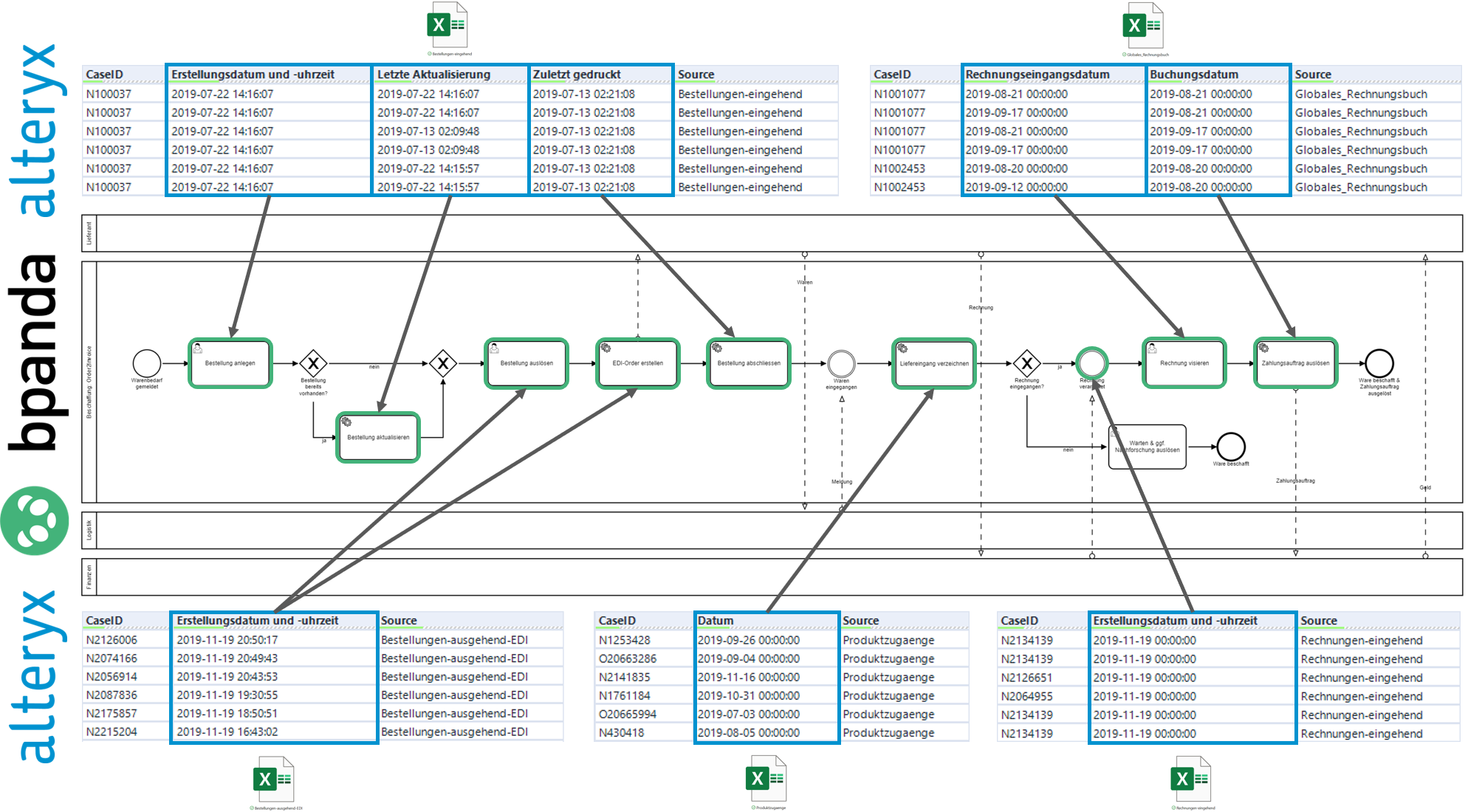
Aus den relevanten Systemen konnten tabellarische Daten exportiert werden, die nun als Input-Files für die Datenaufbereitung mit Alteryx Designer und für die anschliessende Prozessanalyse mit Celonis Snap genutzt werden können.
Die Spalte «Bestellung» ist eindeutig und in jedem Input-File vorhanden. Wir nutzen diese nun als Case-ID, eine der drei Anforderungen, die im Minimum erfüllt sein müssen, damit Celonis Snap genutzt werden kann. Wäre dies nicht der Fall, dann könnte man den Prozess nicht von Anfang bis Ende mit den Logdaten rekonstruiert werden.

Nebst einer Case-ID benötigt ein Ereignis jedoch auch einen Zeitstempel und eine Aktivitätsbezeichnung, wann hat das Ereignis stattgefunden und was ist bei diesem effektiv passiert. In unseren Input-Files gibt es verschiedenste Zeitdaten. Damit der richtige Zeitstempel bestimmt werden kann, ist ein gewisses Knowhow bzw. Verständnis für den zu analysierenden Prozess unabdingbar. Es empfiehlt sich hier Nichts zu überstürzen, denn falls hier falsche Zeitstempel den jeweiligen Aktivitäten zugewiesen werden, ist die Prozessanalyse einerseits für die Katze und andererseits könnten noch falsche Schlüsse daraus gezogen werden.
Durch die Definition der Case-IDs und der Zeitstempel aus den fünf Input-Files entlang des modellierten Prozesses haben wir implizit schon die entsprechenden Aktivitäten zugwiesen.
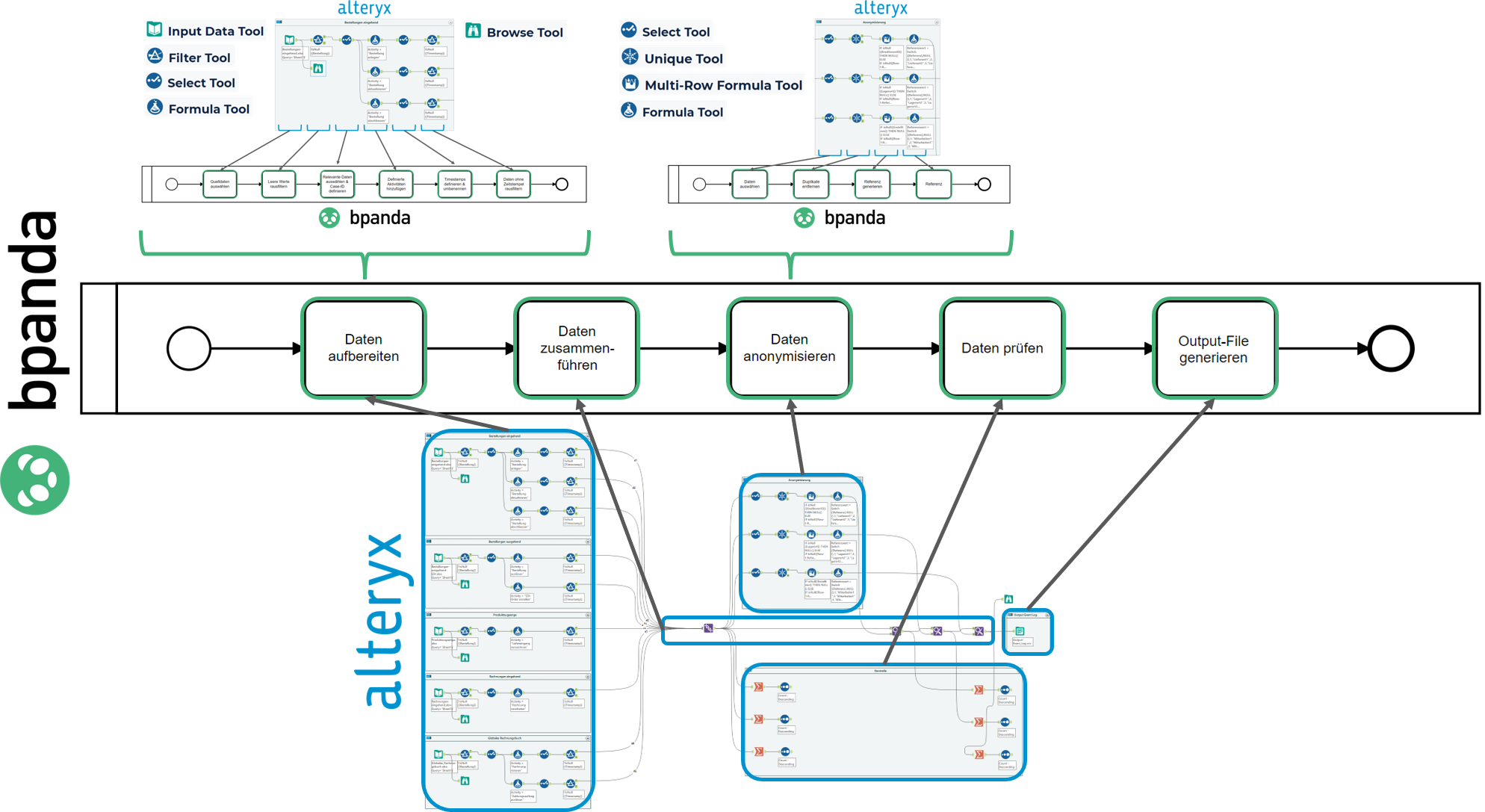
Bevor wir die vorherig definierten Aktivitäten explizit zuweisen können, bereiten wir zuerst die Daten im Alteryx Designer auf. Zur Veranschaulichung haben wir diesen Prozess auch modelliert und zeigen euch diesen am Beispiel des ersten Input-File auf.

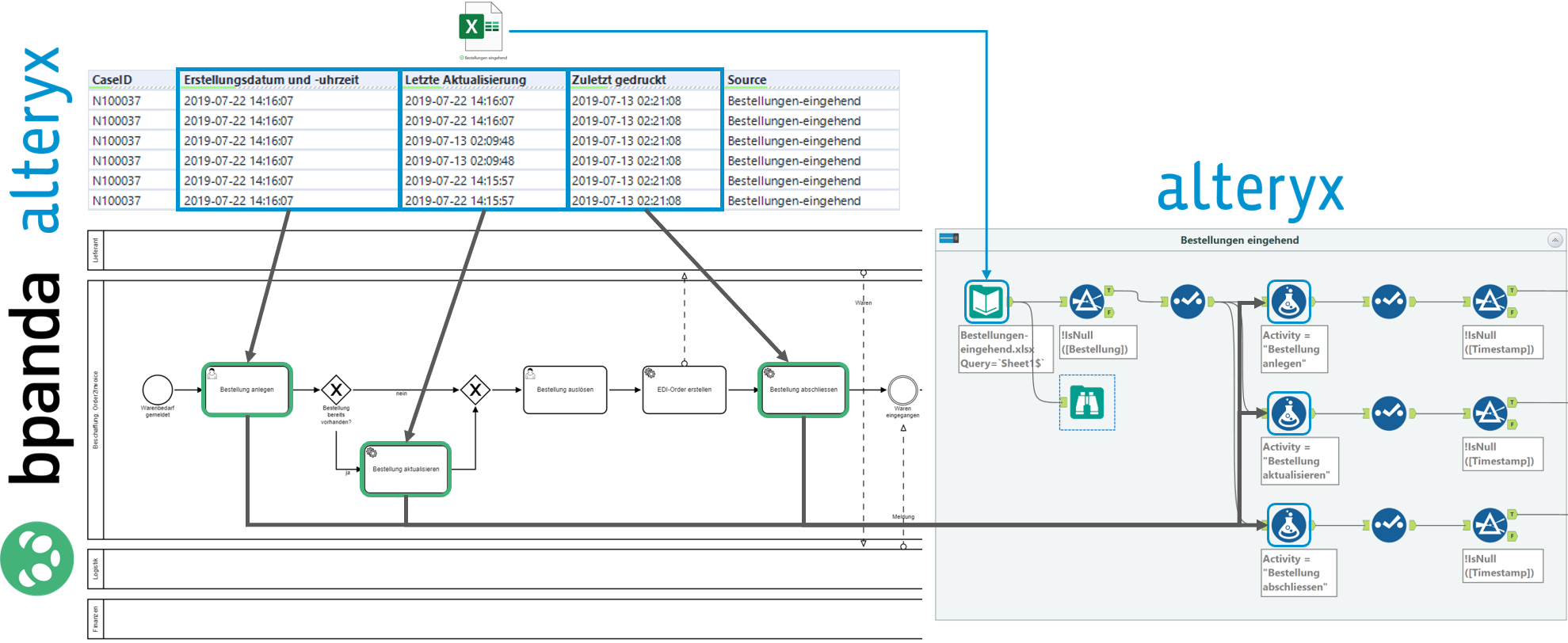
Via Drag & Drop kann das entsprechende Input-File in den Arbeitsbereich von Alteryx gezogen werden, welches sich dann aufgrund seines CSV-Formates automatisch in «Input Data Tool» umwandelt. Danach werden mit dem «Filter Tool» ganz einfach die leeren Werte rausgefiltert, worauf hin mit einem «Select Tool» einerseits alle irrelevanten Spalten abgewählt und die Case-ID definiert werden. Da aus der ersten Quelle bzw. System für drei Aktivitäten innerhalb des zu analysierenden Prozesses Zeitstempel vorhanden sind, teilt sich der Workflow entsprechend auf. Mit einem «Formula Tool» werden die im Schritt 1 definierten Aktivitäten nun im Alteryx-Workflow hinzugefügt, aber dazu später mehr. Danach sind nur noch die definierten Zeitstempel, die verschiedenste Bezeichnungen haben, mit einem «Select Tool» einheitlich umzubenennen und Daten ohne Zeitstempel mit einem «Filter Tool» rauszufiltern.
e.) In Schritt 1 definierte Aktivitäten hinzufügen
Der vorher beschriebene Prozessschritt «Definierte Aktivitäten hinzufügen» wird im Folgenden nun für das erste Input-File veranschaulicht.

Dadurch lässt sich gut erkennen, wo welcher Zeitstempel ein Ereignis im Prozess eine Aktivität ausmacht und wie deren Bezeichnung dann im Alteryx-Workflow entsprechend integriert wird.
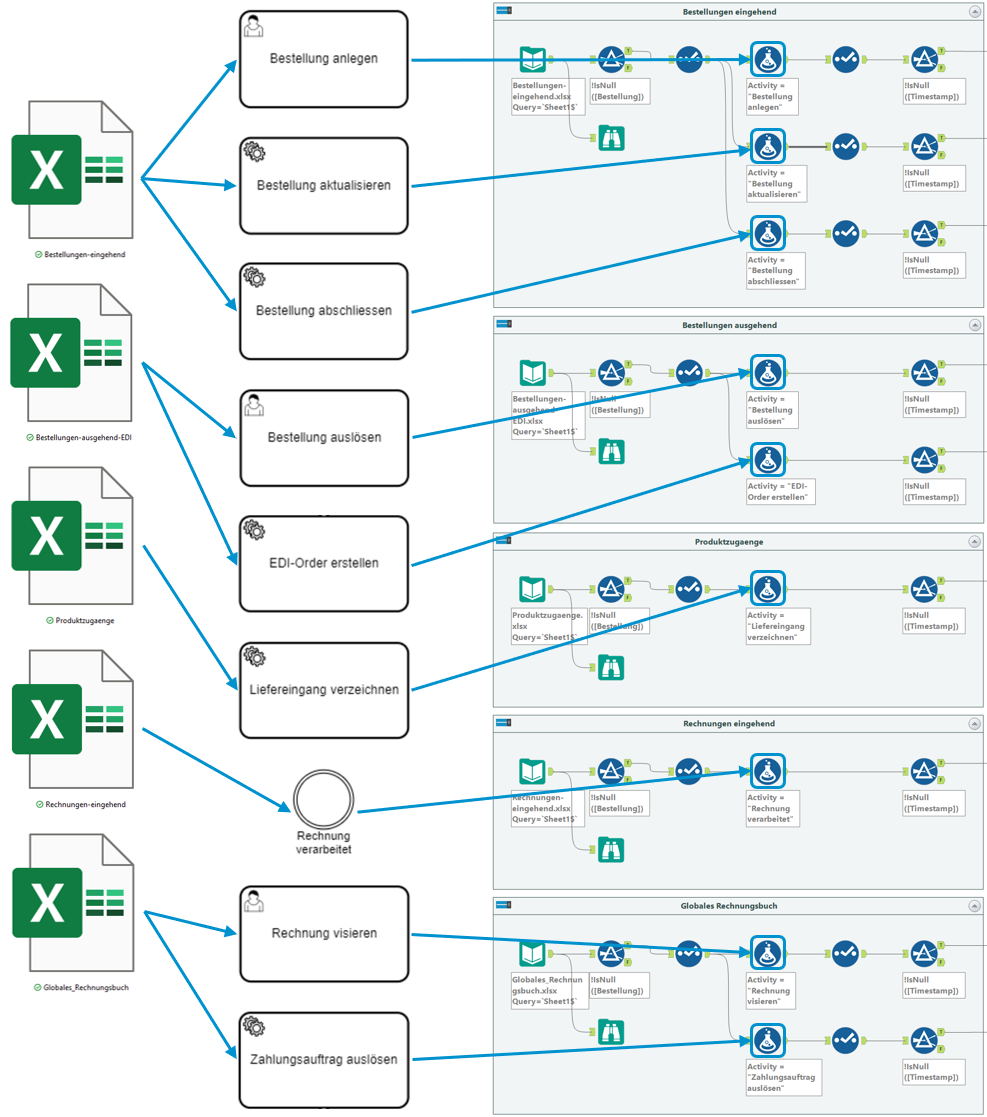
Da wir allerdings mehrere Input-Files und Aktivitätsbezeichnungen beim Prozess «Beschaffung: Oder2Invoice» haben, muss dieses Prozedere entsprechend oft modelliert werden.

Die Daten der einzelnen Input-Files sind nun aufbereitet und müssen nun zusammengeführt und anonymisiert werden.
f.) Daten zusammenführen, anonymisieren und prüfen
Dazu werfen wir nun einen Blick auf den gesamten Altery-Workflow, den wir auch mit einem BPMN-Diagramm visualisiert haben.

Da dieser so etwas schwierig zu verstehen ist, wird dessen Aufbau im nachfolgenden Video schrittweise erklärt.

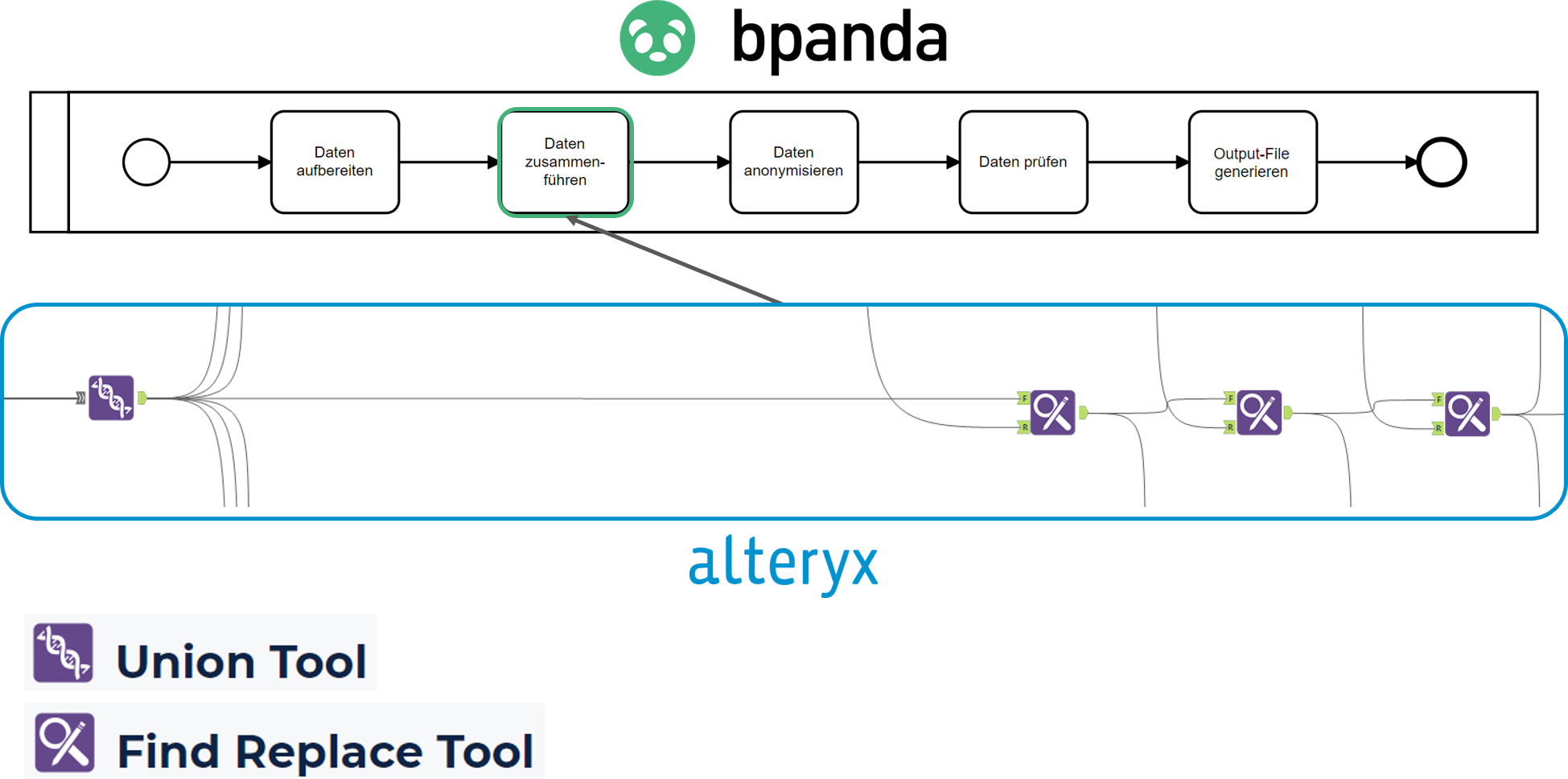
Kommen wir nun zum effektiven Zusammenführen der Daten.

Aufgrund der Harmonisierung der Daten im vorherigen Schritt, eignet sich nun das «Union Tool» die Datensätze unkompliziert zusammenzuführen. Mit dem «Find Replace Tool» werden die sensiblen mit den anonymisierten Daten ersetz.

Wie werden die Daten anonymisiert? Zuerst ist zu bestimmen, welche Daten überhaupt zu anonymisieren sind. Danach werden alle Duplikate entfernt und Referenzen generiert. Anschliessend wird zu jeder Referenz ein entsprechend Referenzwert («Lieferant1», «Lagerort1» & «Mitarbeiter1» etc.) zugewiesen.
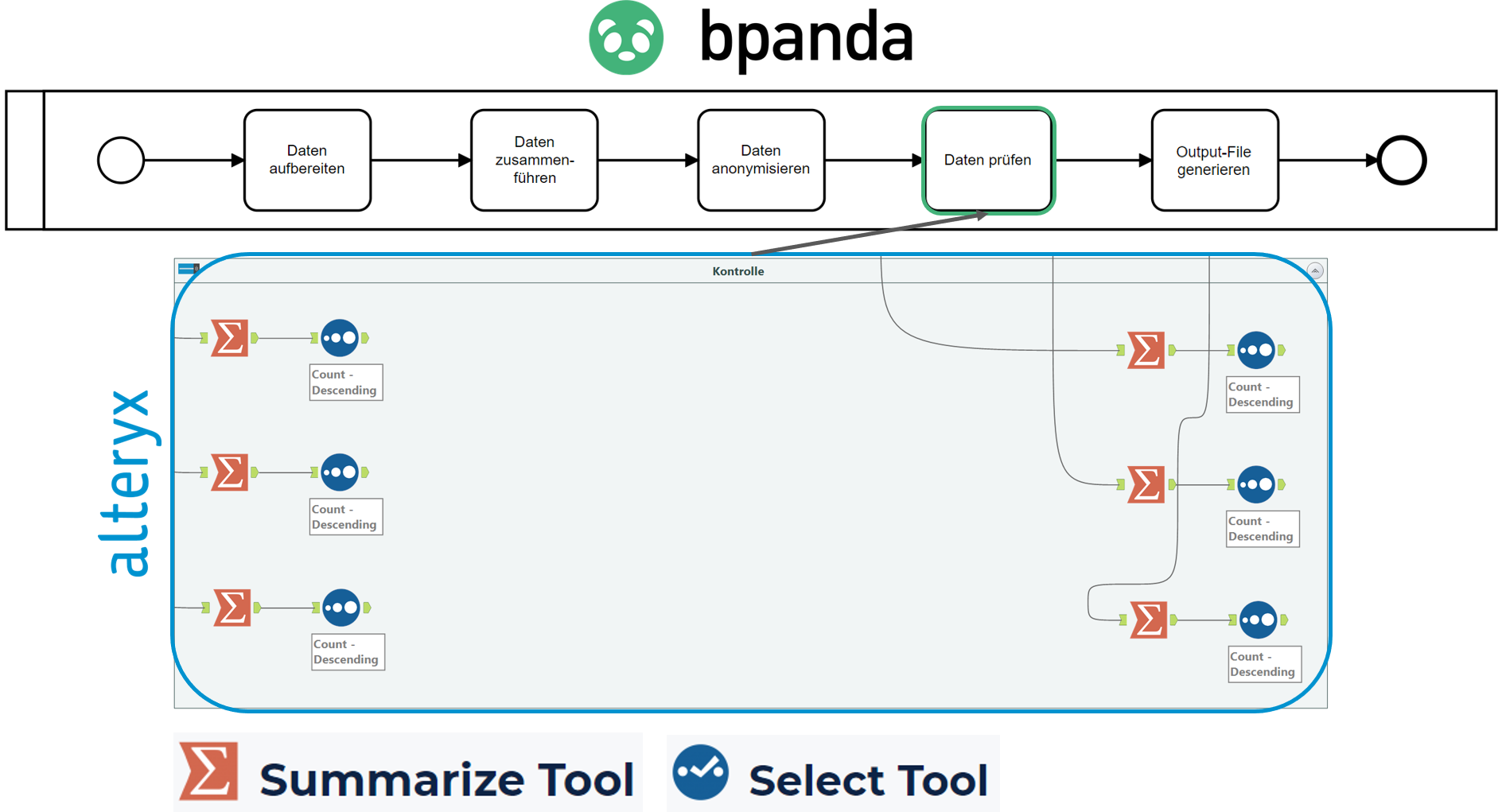
Hier wird mit dem «Summarize Tool» schlichtweg die Anzahl der Datensätze vor und nach der Anonymisierung geprüft.
g.) Output-Files generieren (.csv)

Mit dem «Output Data Tool» wird ein CSV-File am definierten Zielort abgelegt.
Schritt 3: Prozessanalyse mit Celonis Snap durchführen
a.) CSV-Files hochladen & b.) «Case ID», «Activity» und «Timestamp» manuell zuweisen

Wir haben nun gesehen, wie man in Celonis Snap eine CSV-File hochlädt und die notwenigen Parameter manuell zuweist.
Im folgenden Video zeigen wir euch, wie man im Process Explorer die Fallanzahl, Durchlaufzeiten und die Nachbearbeitungsrate analysiert.

Du hast nun gesehen, was es alles vorab bedarf, um Process Mining betreiben zu können. Celonis hat zwar einige Prozess Konnektoren im Petto und baut diese laufend aus, ist aber bei weitem keine Plug-and-Play Lösung. Wenn man also Process Mining in einer etwas komplexeren Anwendungsarchitektur durchführen möchte, ist eine die Harmonisierung der Ereignisdaten dafür unabdingbar.
Willst Du gemeinsam mit uns Erfahrungen im Bereich Process Mining sammeln? Oder hast Du Celonis bereits im Einsatz und möchtest mit Alteryx nun das volle Potential davon nutzen?
Dann melde Dich bei uns. Gerne gehen wir individuell auf deine Bedürfnisse ein und zeigen dir mögliche Lösungswege auf.
Bilder-Gallery