
Von Stefan Habermacher
28 Dezember 2021In diesem Beitrag wird aufgezeigt, wie man effizient und in fast Echtzeit Datenflüsse in ein relationales Datenbanksystem einspeisen kann. Das heisst, die Daten werden dann geladen und verarbeitet, wenn diese anfallen und stehen dem Unternehmen für analytische Zwecke schnell zur Verfügung. Dieses Vorgehen wird als real-time / near real-time Verarbeitung bezeichnet. Im Kontrast zu (near) real-time Loads stehen die Batch Loads, in welchen die Daten zum Zeitpunkt X (beispielsweise täglich oder wöchentlich) in entsprechend grossen Mengen geladen und verarbeitet werden. Statt also mit Daten zu arbeiten, die über 24 Std. alt sein können, erlaubt (near) real-time Verarbeitung, sehr aktuelle Daten zu nutzen. Dies ermöglicht Unternehmen schnellere Reaktionszeiten und steigert die Aktualität des Informationsgehaltes massgeblich. Dabei können Daten aus unterschiedlichen Quellsystemen über den gleichen Stream geladen und verarbeitet werden.
Konkret wird aufgezeigt, wie Exasol mit der Streaming Plattform Kafka zusammen funktionieren kann. Im folgenden Use Case wird die Integration von Exasol als Sink- und Source System, also als Ziel- oder Quellsystem, für Kafka vorgestellt respektive in einem Test-Beispiel implementiert.
Exasol ist eine für analytische Zwecke entwickelte und optimierte Datenbank (RDBMS). Dabei setzt Exasol auf spaltenorientiertes Speichern sowie In-Memory Technologie. Dies ermöglicht eine Komprimierung der Daten und bietet Performance Vorteile gegenüber anderen Speichermedien wie Hard-Disk-Drives (HDDs) oder Solid State Disks (SSDs). Des Weiteren bietet Exasol Parallelisierung und entsprechende Lastverteilung an, um die Leistung noch weiter zu optimieren. Dies macht Exasol zu einem idealen Sink oder Source System für Streaming Plattformen wie Kafka.
Zielsetzung
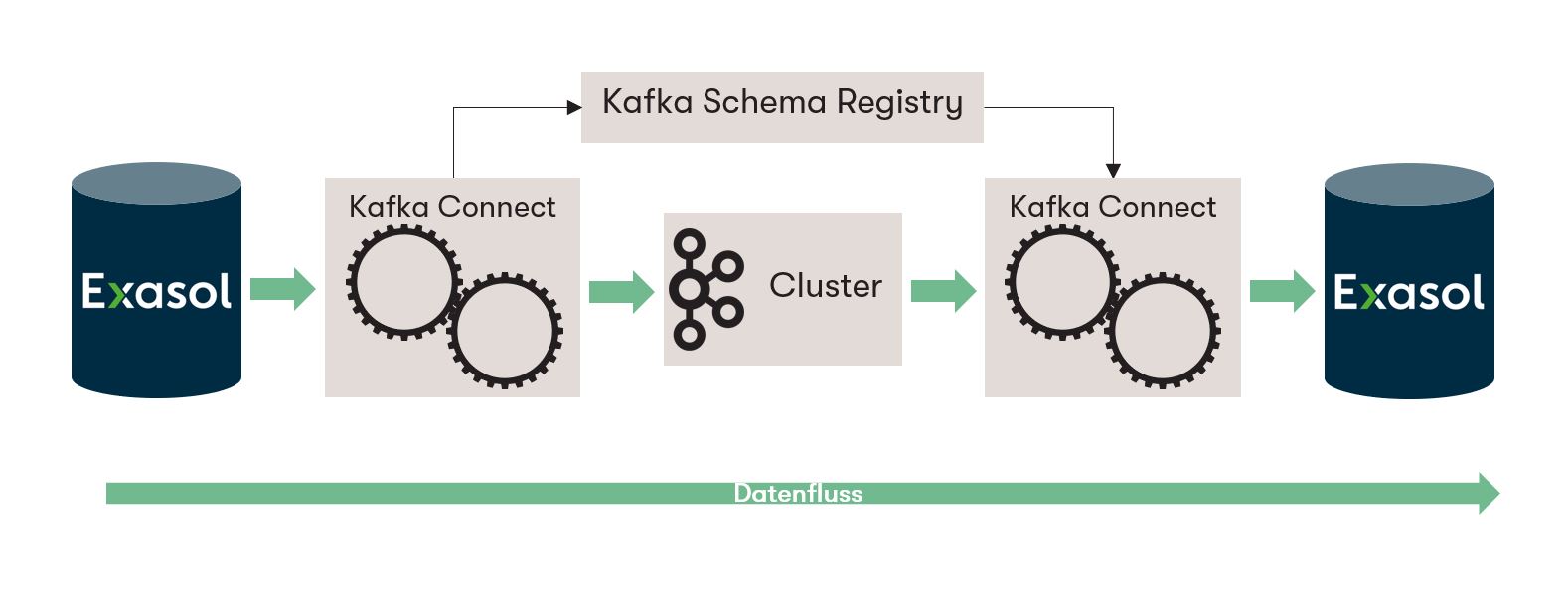
Damit Exasol als Sink sowie Source System eingesetzt werden und dies in einer lauffähigen Umgebung simuliert werden kann, sind folgende Komponenten wichtig:
- Exasol DB Instanz
- Kafka Manager
- Kafka Zookeeper
- Kafka Connect und Kafka Connect UI
- Kafka Schema Registry
- Kafka Broker
Dabei spielen die Schema Registry und Kafka Connect eine zentrale Rolle:
Die Schema Registry [1][2] verwaltet unter anderem die Datenstrukturen und leitet diese an die Sink Connectors weiter. Des Weiteren ermöglicht sie unter gewissen Bedingungen [3] Schema Evolution. Das heisst, veränderte Datenstrukturen (es wird in der Quelle z.B. eine Spalte ergänzt oder gelöscht) werden automatisch erkannt und es wird eine neue Version des Schemas angelegt. Damit können Fehler verhindert werden und der Stream läuft weiter.
Kafka Connect ist zuständig für das Lesen, Schreiben, Serialisieren, Deserialisieren der Daten. Beim Serialisieren werden strukturierte Daten in einen Bytestrom umgewandelt, beim Deserialisieren passiert genau das umgekehrte. Zusätzlich bietet sich die Möglichkeit, gewisse Transformationen vorzunehmen. Die Schlüsselkomponenten lassen sich wie folgt zusammenfassen [4]:
- Connectors – die JAR-Dateien, die festlegen, wie die Integration mit dem Datenspeicher selbst erfolgen soll
- Converter – Handhabung der Serialisierung und Deserialisierung von
- Daten Transforms – optionale Manipulation von Nachrichten
Einfacher ausgedrückt, der Connector spricht die Sprache des Sink oder Source Systems (z.B. Exasol) und kann auf diesen Lesen respektive Schreiben. Doch damit kann Kafka nichts anfangen, da Kafka nur Key Value Pairs in Form von Bytes speichert. Key Value Pairs sind sogenannte Schlüssel-Wert-Paare. Dies entspricht zwei verknüpften Datenelementen. Dabei dient der Schlüssel zur Identifizierung und der Wert repräsentiert die Information. Dieser Prozess, das Serialisieren und Deserialisieren, wird von den Convertern übernommen. Es gibt unterschiedliche Serialisationsformate welche von Kafka Connect unterstützt werden wie z.B. Avro, JSON oder Protobuf.
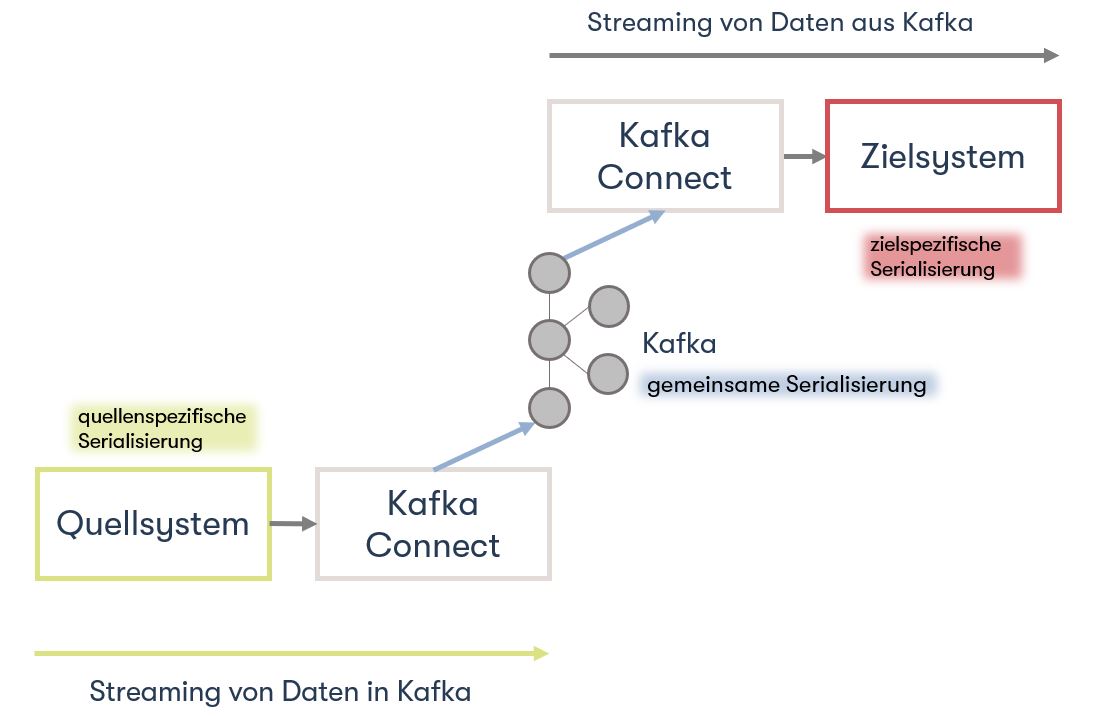
PoC Implementation
Mit dem Standard JDBC-Treiber, welcher auf Kafka Connect installiert werden muss, lässt sich Exasol bereits als Source System implementieren. Damit Exasol auch als Sink System verwendet werden kann, ist aber eine Erweiterung des Standardtreibers nötig. Dazu gibt es eine Open Source Projekt, eine Software mit öffentlich zugänglichem Quelltext. Alle nötigen Infos hierzu sind hier zu finden: Apache Kafka Integration | Exasol Documentation
Eine detaillierte Anleitung, um die Integration umzusetzen: GitHub - exasol/kafka-connect-jdbc-exasol: Exasol dialect for the Kafka Connect JDBC Connector. Dort ist zusätzlich ein YAML File zu finden. Um einfach und schnell alle nötigen Docker Containerts zu starten.
Damit Exasol als Sink oder Source System verwendet werden kann, müssen natürlich entsprechende Connectors angelegt werden:
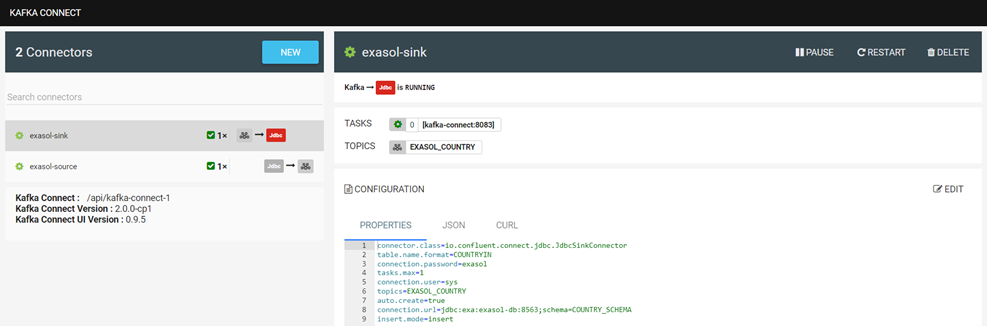
Es gibt unterschiedliche Konfigurationsmöglichkeiten für die Eigenschaften. Mehr Details dazu: JDBC Sink Connector Configuration Properties | Confluent Documentation
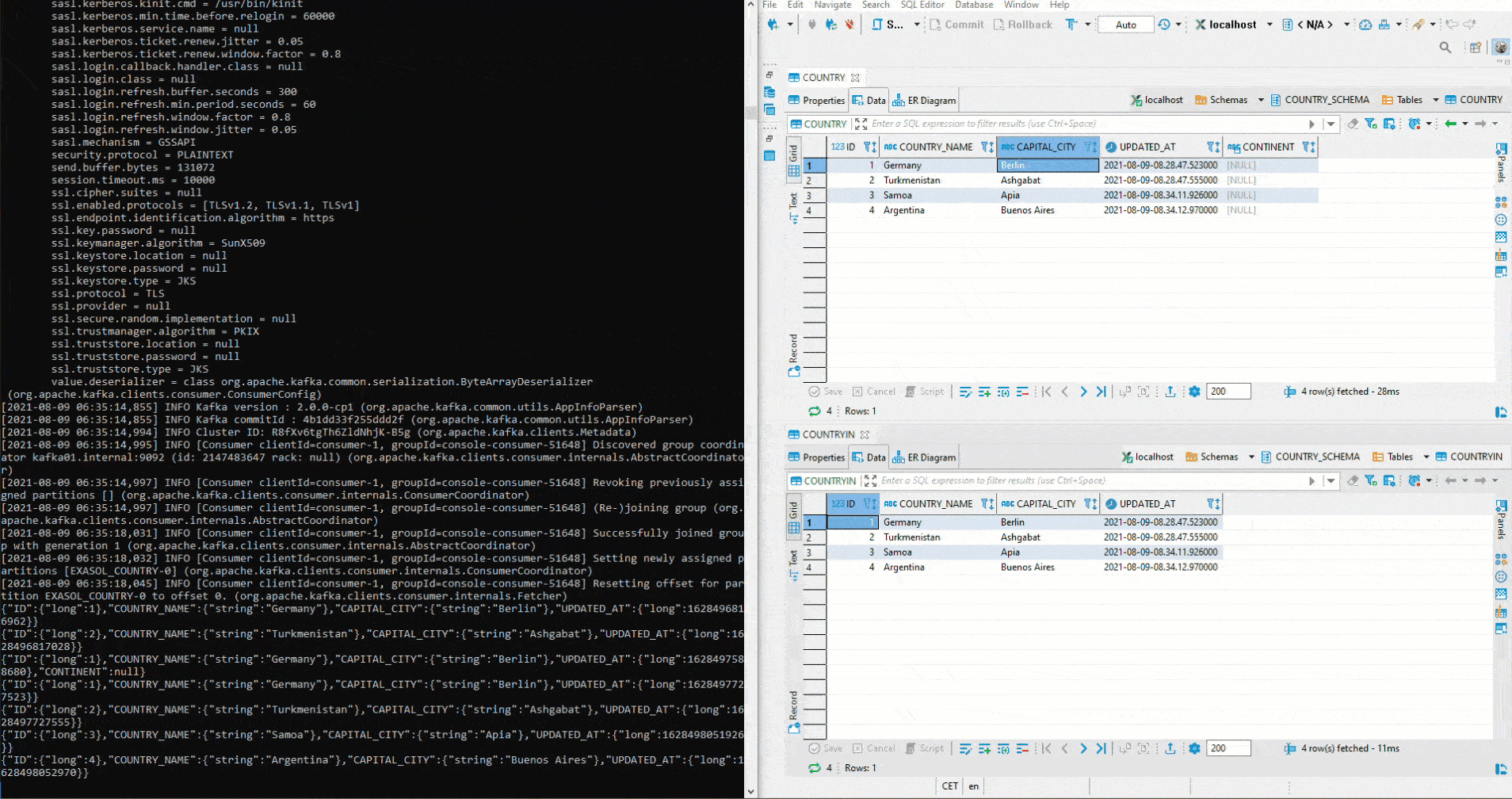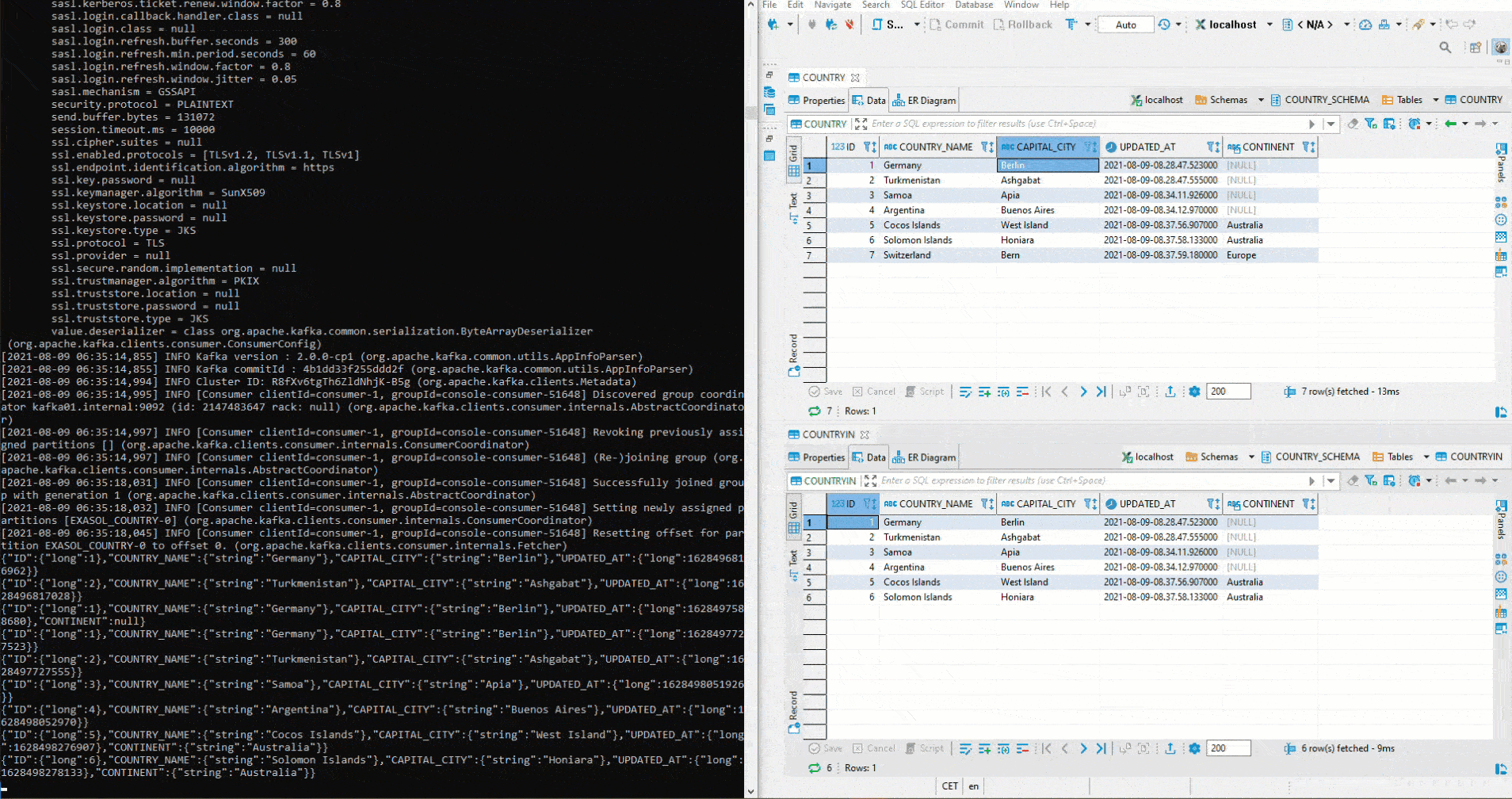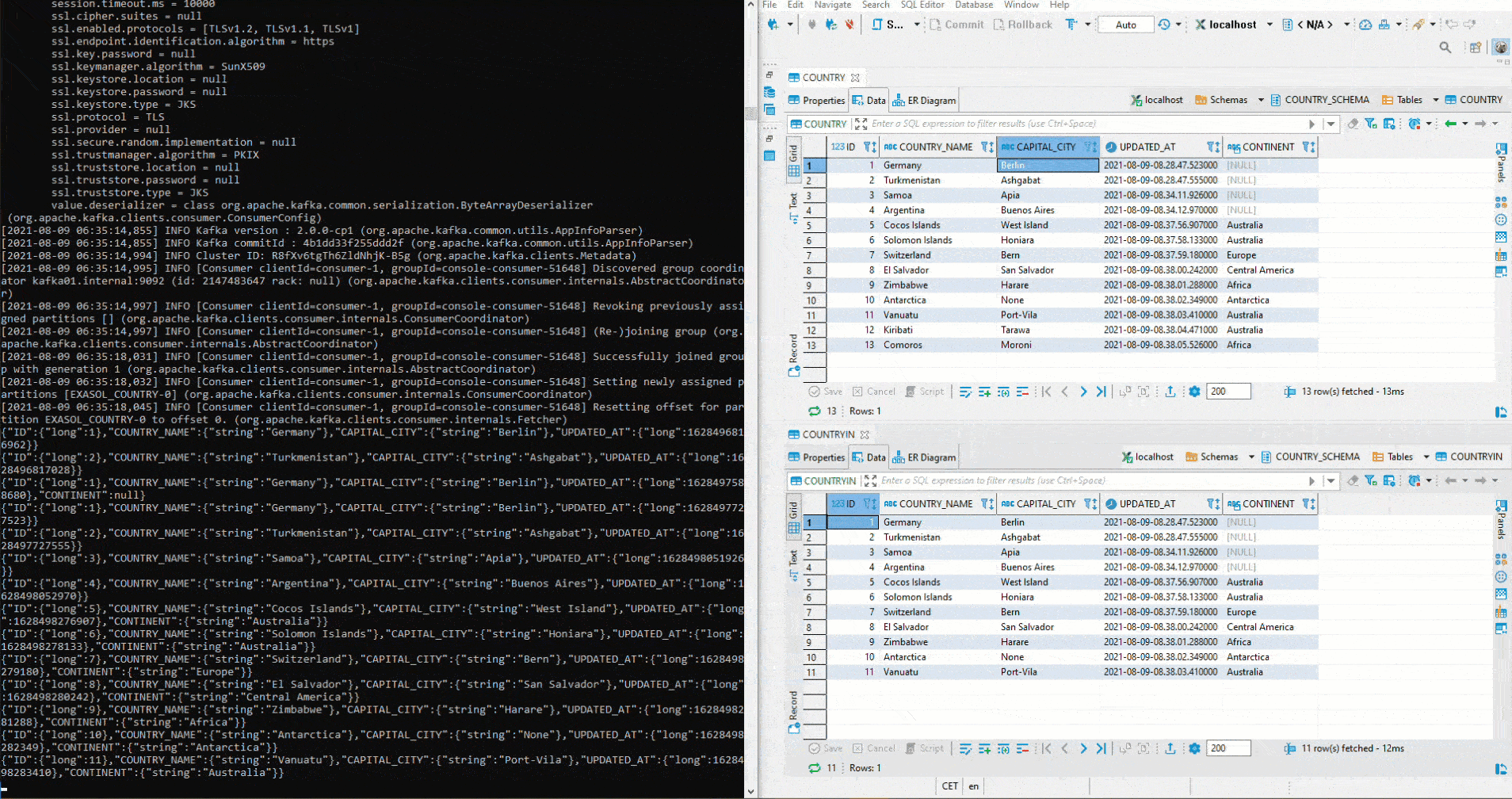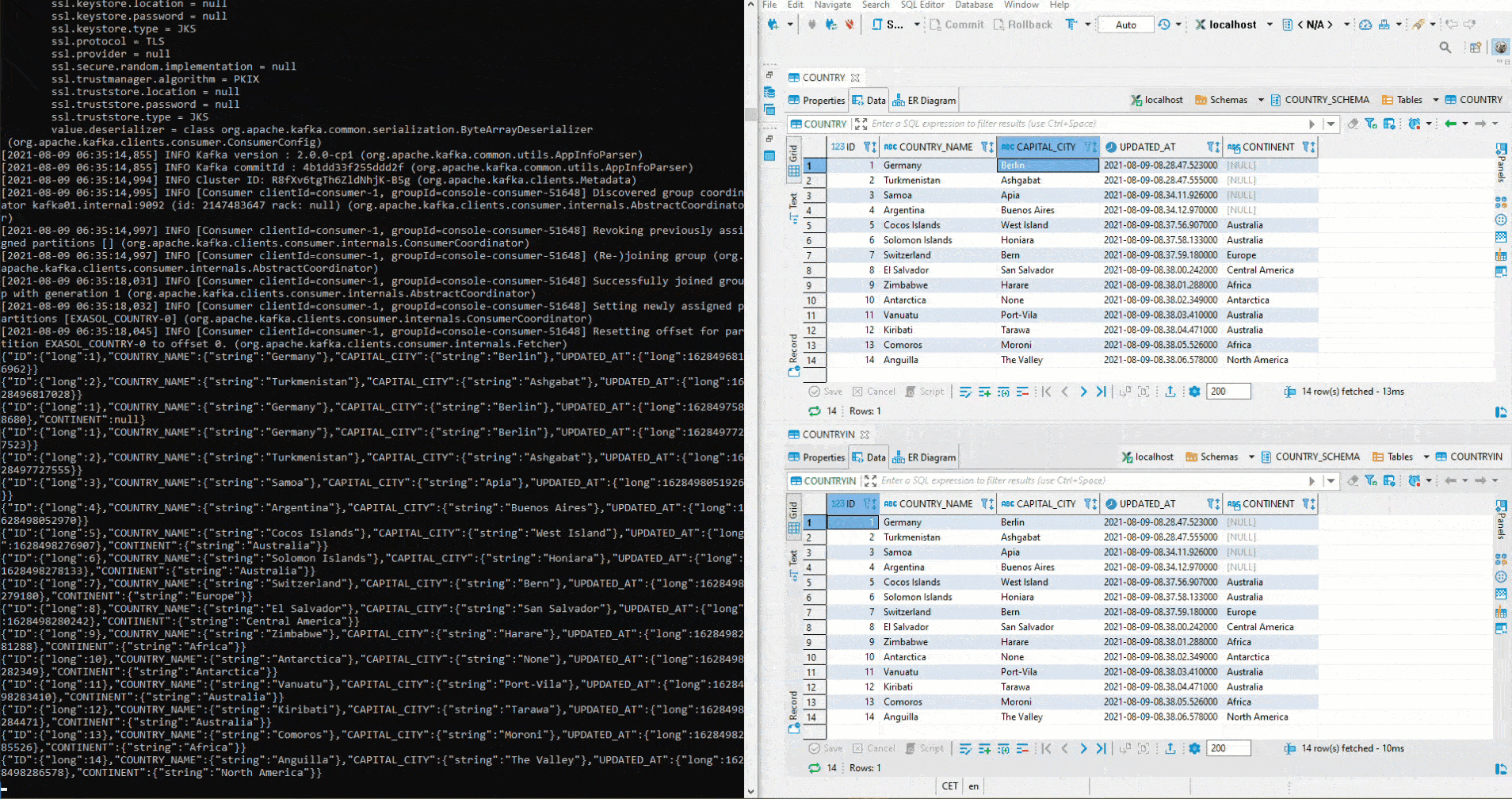
Wurde alles bereitgestellt und laufen die Connectors, lässt sich das Setup relativ einfach testen. In der folgenden Grafik werden in der linken Hälfte mittels Python und pyexasol unterschiedliche Werte in den Table COUTRY eingefügt. In der rechten Hälfte läuft ein Avro Deserializer, welcher gemäss Schema die Werte deserialisiert und ausgibt:
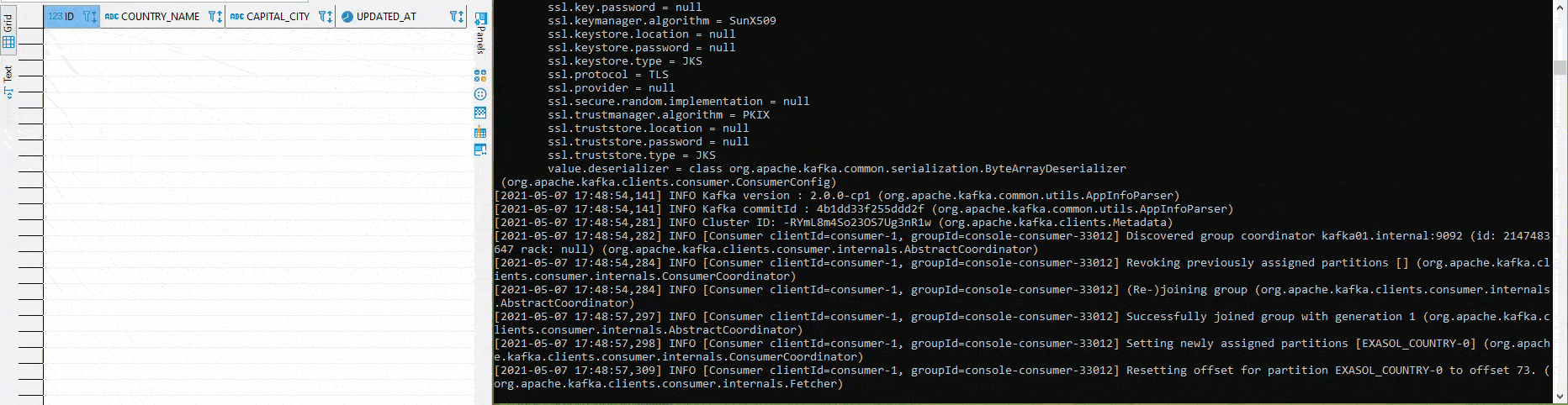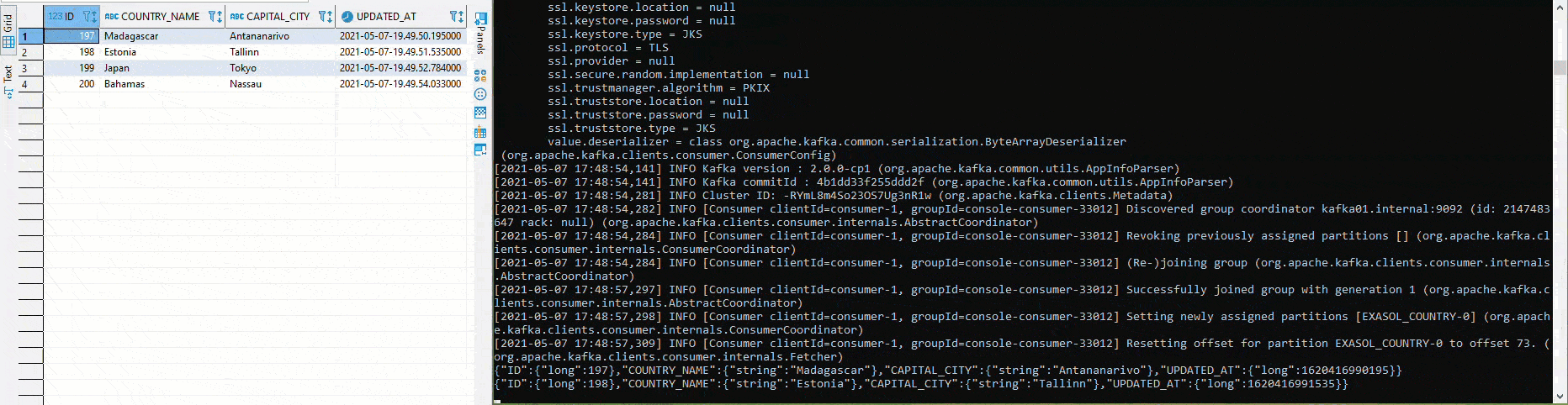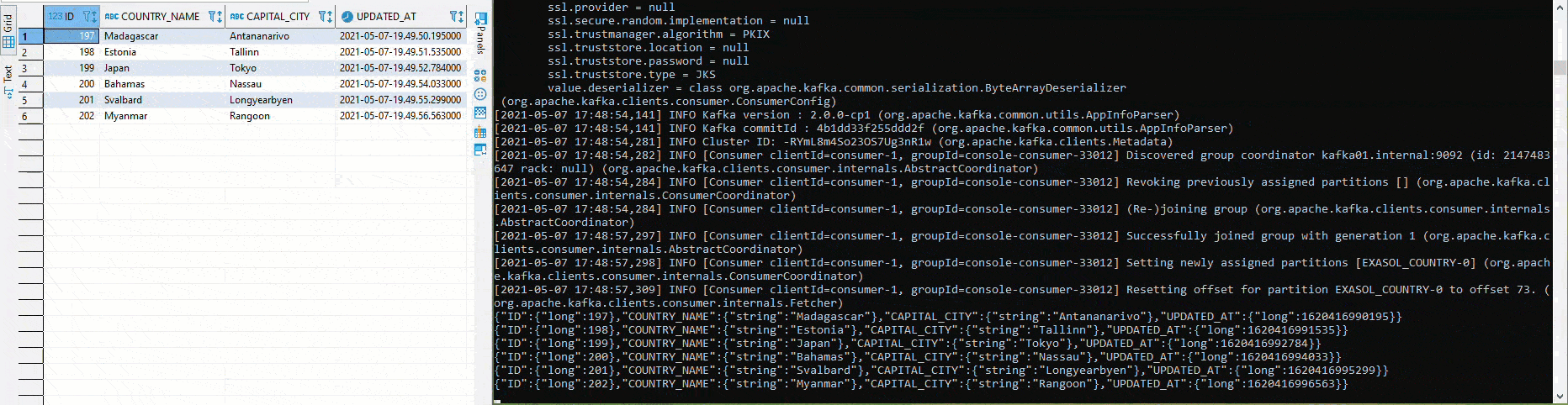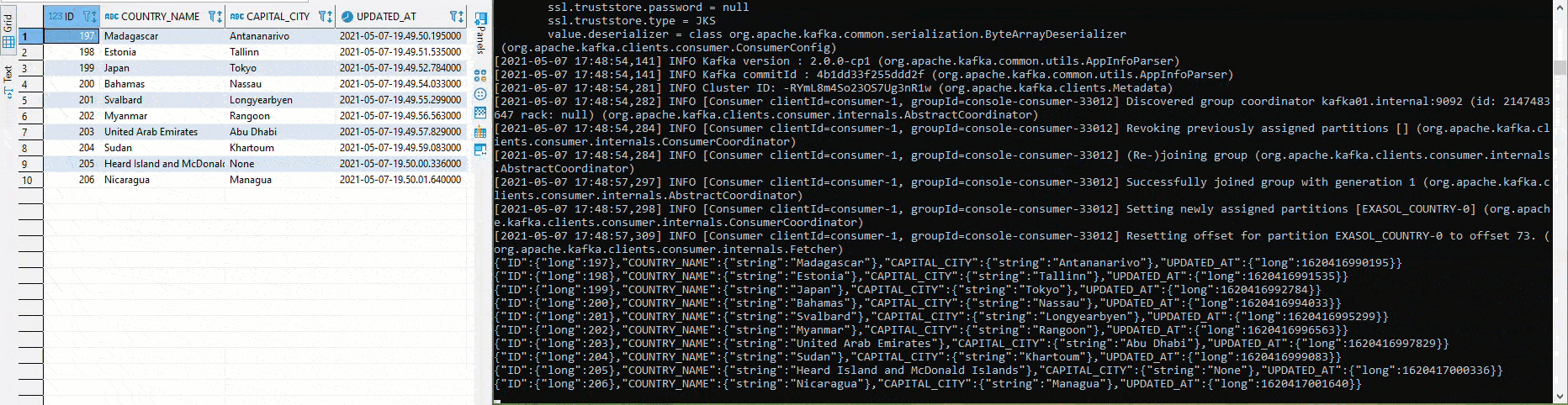
Dabei kann dem Table «COUNTRY» beispielsweise eine neue Spalte «POPULATION» hinzugefügt werden, ohne dass manuelle Anpassungen am Source Connector nötig sind. Das Schema wird, sofern gemäss Einstellungen kompatibel, automatisch angepasst und eine neue Version wird angelegt:

Um das Setup für Exasol als Sink zu testen, kann man auf der Schema Registry einen Kafka Avro Console Producer starten und Werte im entsprechenden Format einfügen. In der folgenden Grafik wird dies ebenfalls mittels Python veranschaulicht. Auf der linken Seite sieht man den Avro Producer. Dort werden via Copy Paste Werte eingefügt. Auf der rechten Seite der definierte Table im Connector:
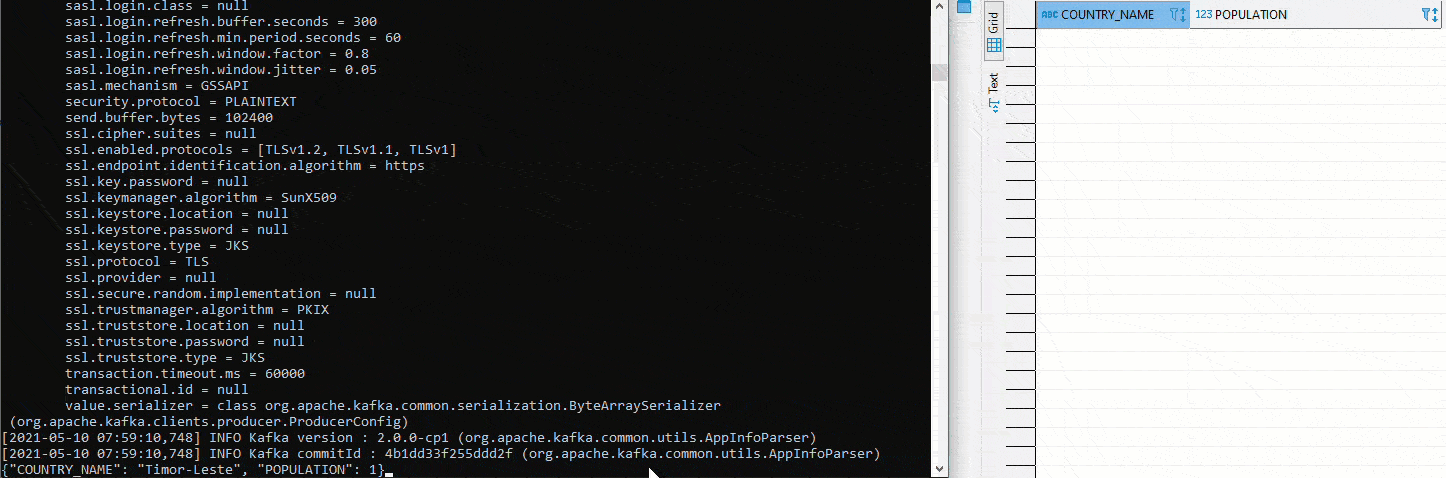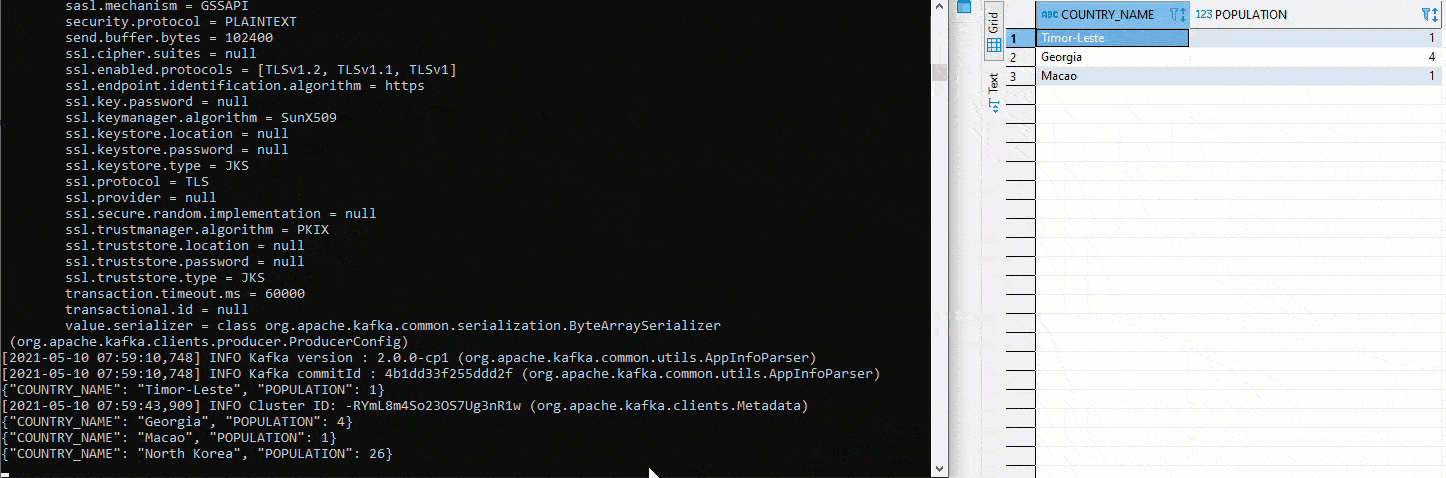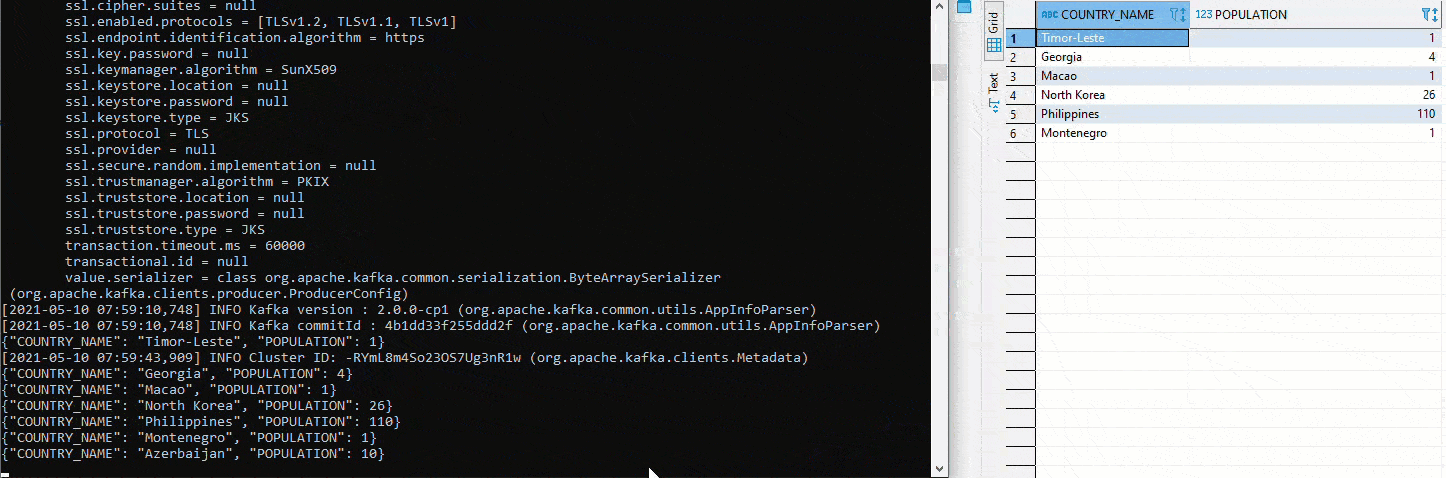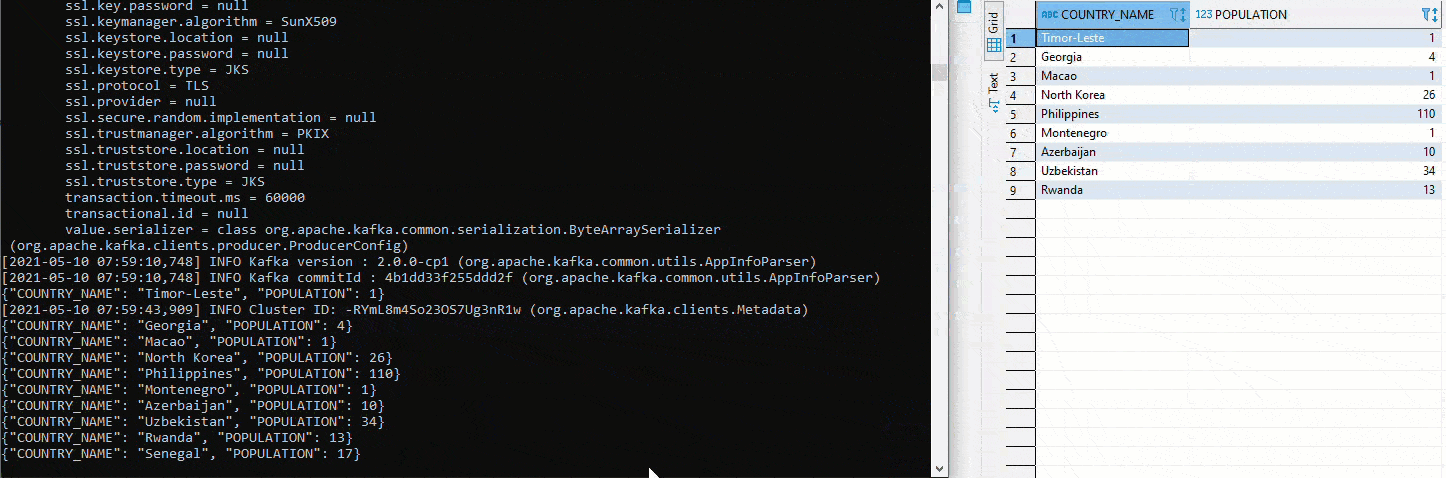
Hier wurde mit zwei unterschiedlichen Topics getestet. Um das anfängliche definierte Setup umzusetzen, muss zuerst im Kafka Manager ein Cluster angelegt werden. Anschliessend werden beide Connectors auf das gleiche Topic gestellt. Da auf dem Sink Connector auto.create auf true gestellt wurde, wir der Sink Table automatisch angelegt. Jetzt startet man erneut ein Avro Deserializer auf der Schema Registry. Auf der rechten Seite sehen wir oben den Table COUNTRY. Dort werden erneut Werte mittels Python eingefügt. Unterhalb ist der Table COUNTRIN der als Zieltable für den Sink Conncetor definiert worden. Damit fliessen die Daten von COUNTRY in den Kafka Cluster und von dort weiter in den COUNTRIN Table.
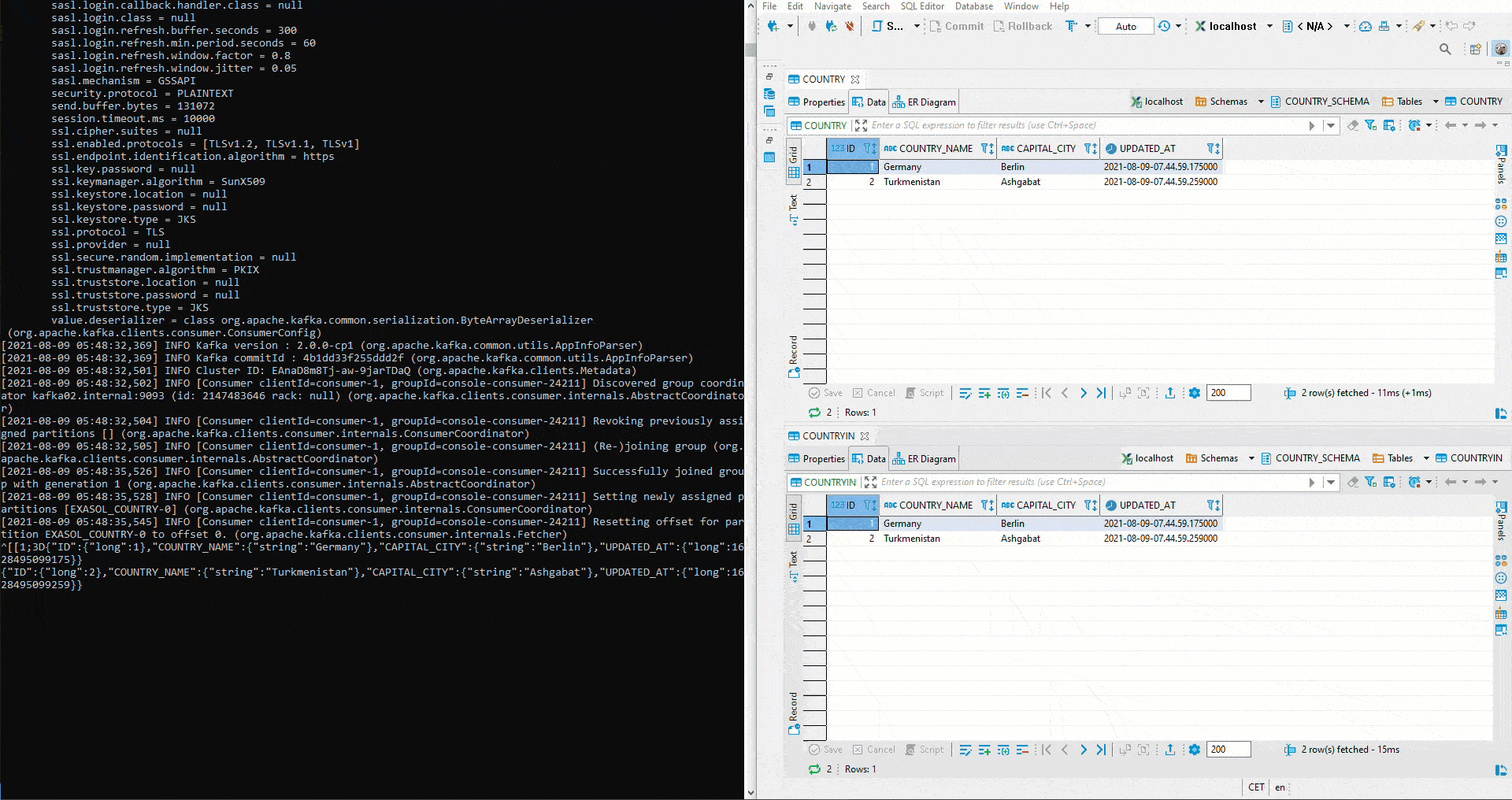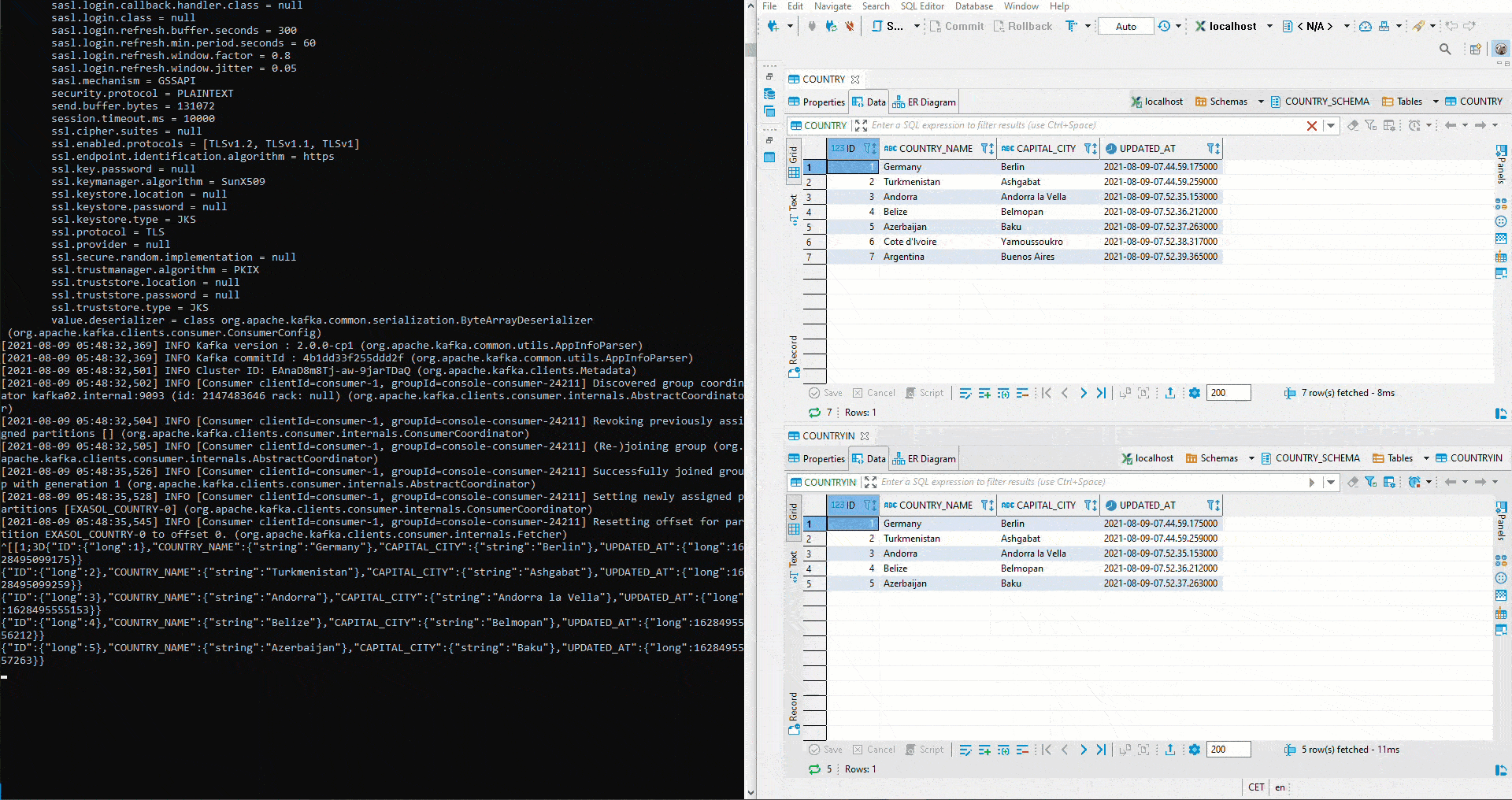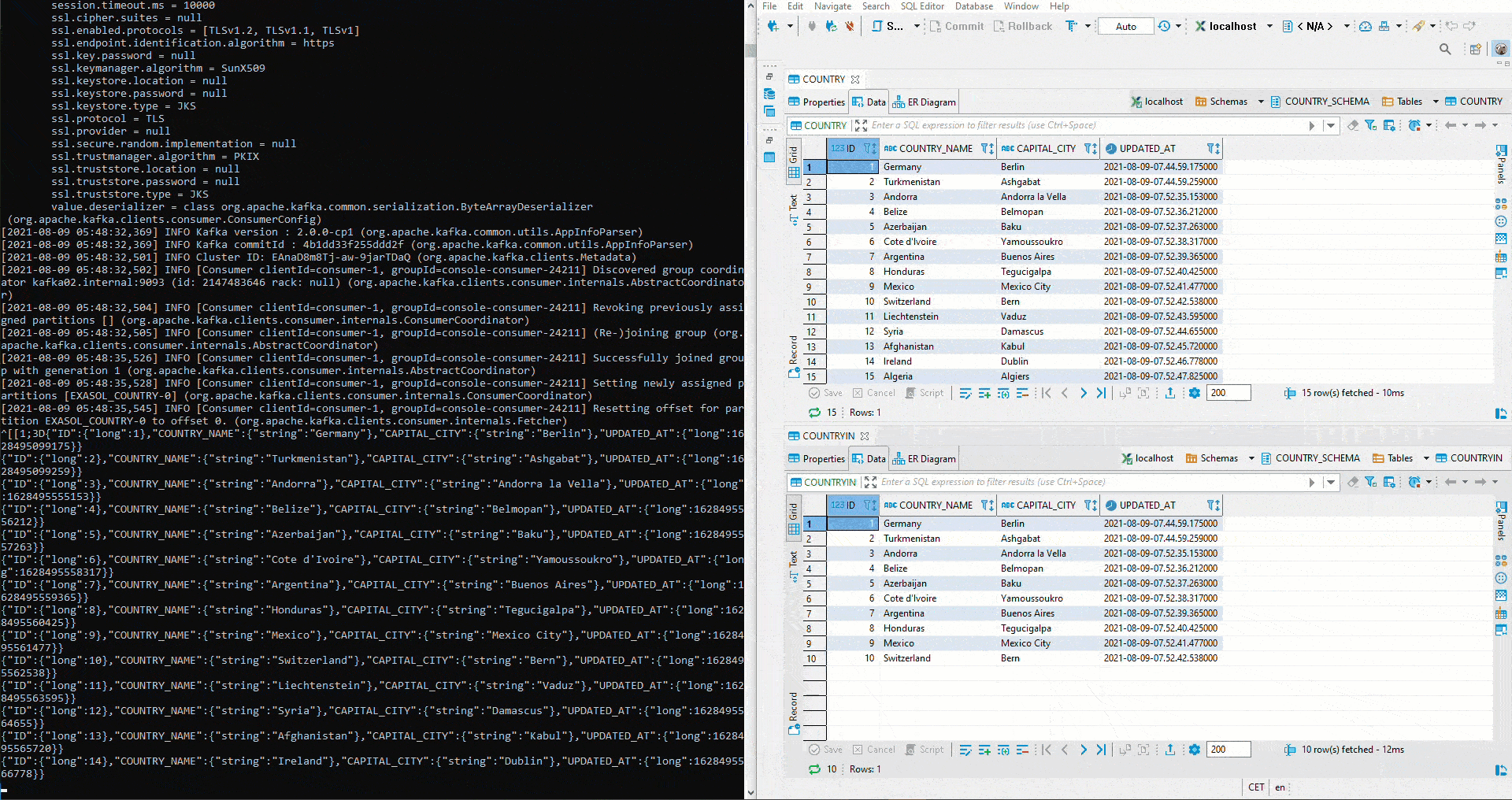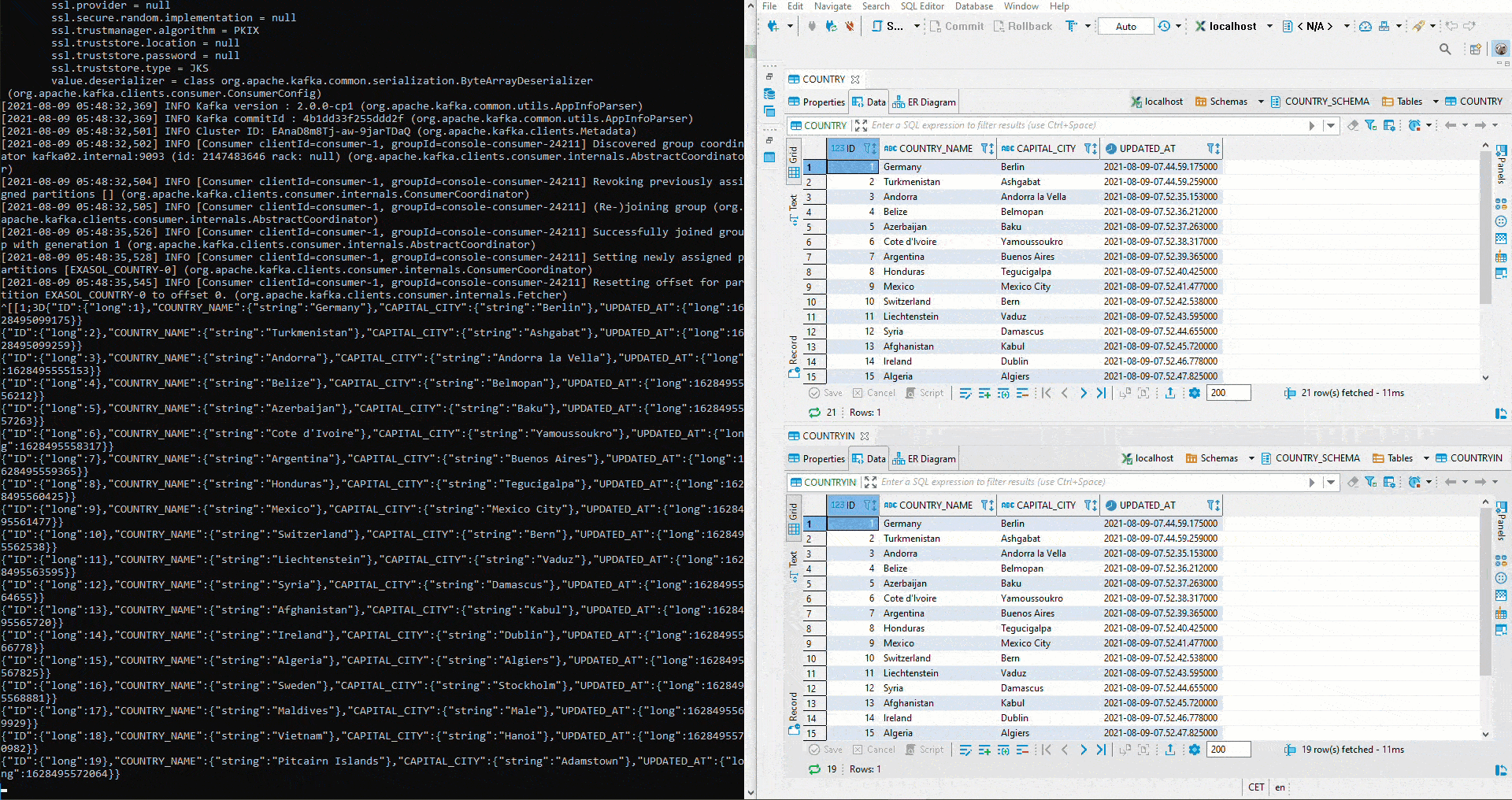
Doch wie verhält sich das Sink System in Bezug auf veränderte Schemas? Zuerst wird der Parameter von auto.evolve im Sink Connector auf true gestellt:
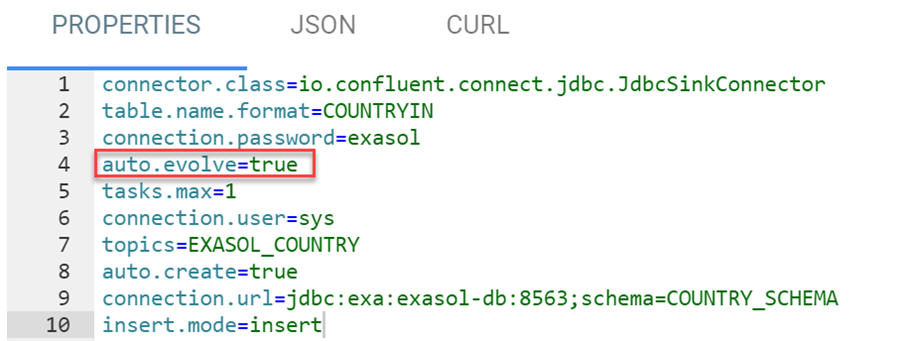
Anschliessend wird dem Source Table COUNTRY eine Spalte CONTINENT hinzugefügt. Danach startet man das Python-Script für die Inserts erneut – inklusive Kontinent. Wie zu sehen ist, wird die Spalte automatisch im Sink Table COUNTRYIN angelegt und die Daten werden eingefügt:
Auf der Schema Registry lassen sich Version 1 sowie latest mittels API (Application Programming Interface) anzeigen:
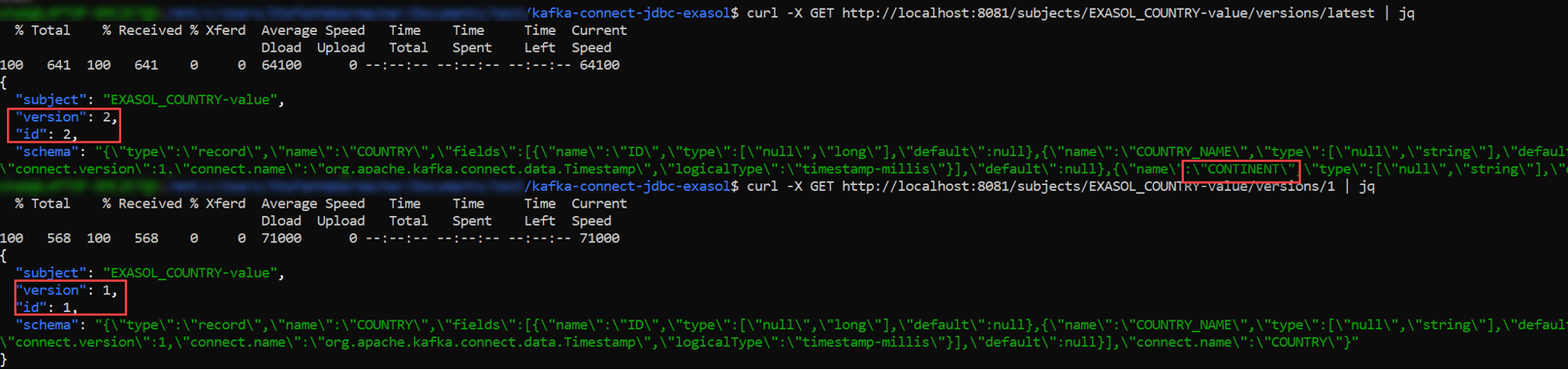
Wie man sieht, ist bei der Version latest (2) die Spalte CONTINENT ersichtlich – dies ist bei Version 1 nicht der Fall.
Fazit
Grundsätzlich lässt sich sagen, dass eine lauffähige Implementation schnell und einfach bereitgestellt werden kann – dank des Open Source Connectors der Exasol Community. Gleichzeitig muss man im Hinterkopf behalten, dass es sich hierbei um die Version 1 handelt und es gewisse Limitation gibt. Beispielsweise werden keine batch.size > 1 in upsert Modus unterstützt. Das heisst, es muss Reihe für Reihe geprüft und geschrieben werden. Dies kann durchaus zu Performanceproblemen führen, wenn es sich um grössere Datenmengen handelt.
Sie finden es spannend stets aktuelle Datensätze zur Verfügung zu haben und möchten sich orientieren, wie das mit den Systemen Ihrer Firma möglich ist?
Wir von der Banian AG helfen Ihnen gerne mit einer Erstberatung weiter. Kontaktieren Sie uns per Telefon +41 (0)61 551 00 12, per Mail , oder schicken Sie uns einfach eine Nachricht hier auf LinkedIn.
Und wenn Ihr Interesse über (near) real-time Processing mit Kafka hinausgeht, helfen wir gerne als Digitalisierungspartner von der Strategie über das Information Management bis hin zu Data & Analytics.
Für Interessierte zum Nach- und Weiterlesen
Links:
GitHub - exasol/kafka-connect-jdbc-exasol: Exasol dialect for the Kafka Connect JDBC Connector
How to integrate Apache Kafka and Exasol
Literatur:
Schema Registry Overview | Confluent Documentation
Using Kafka Connect with Schema Registry | Confluent Documentation
Schema Evolution and Compatibility | Confluent Documentation
Begriffserklärungen:
|
Sink |
Zielsystem für den Datenfluss aus Kafka |
|
Source |
Quellsystem für den Datenfluss in Kafka |
|
Parallelisierung |
Gleichzeitig laufende Prozesse respektive Verarbeitungsschritte und die Leistung zu verbessern |
|
Lastverteilung |
Prozesse werden auf mehrere Instanzen eines Systems verteilt |
|
Serialisieren |
Umwandlung von strukturierten Objekten in einen Bytestrom |
|
Deserialisieren |
Umwandlung eines Bytestroms in ein strukturiertes Objekt |
|
Key Value Pairs |
Schlüssel-Wert-Paar, entspricht zwei verknüpften Datenelemente. Dabei dient Schlüssel zur Identifizierung und der Wert repräsentiert die Information |
|
JDBC-Treiber |
Java Database Connectivity Treiber, dient als grundlegend Schnittstelle zwischen auf Java basierten Applikationen und Datenbanken |
|
Open Source Projekt |
Software mit öffentlich zugänglichem Quelltext |
|
Kafka Avro Console Producer |
Kommandozeilen basiert Kafka Applikation um Daten in ein Topic einzulesen und in Avro umzuwandeln |
Bilder-Gallery